



안녕하세요, AI팀 Machine Learning Engineer 최익규입니다. 해당 아티클은 구글에서 발표한 논문의 흐름을 그대로 따라가면서도, 중간중간 이해를 돕기위한 그림과 제 생각이 추가되어있습니다.
1. Introduction
•
이 논문은 Youtube와 같이 매우 large-scale의 환경에서 video recommendation하는 내용을 다룹니다.
◦
데이블에서도 매우 large-scale 환경에서 광고 추천을 하는데요. 유사한 내용이 많아서 해당 논문을 다루게 되었습니다.
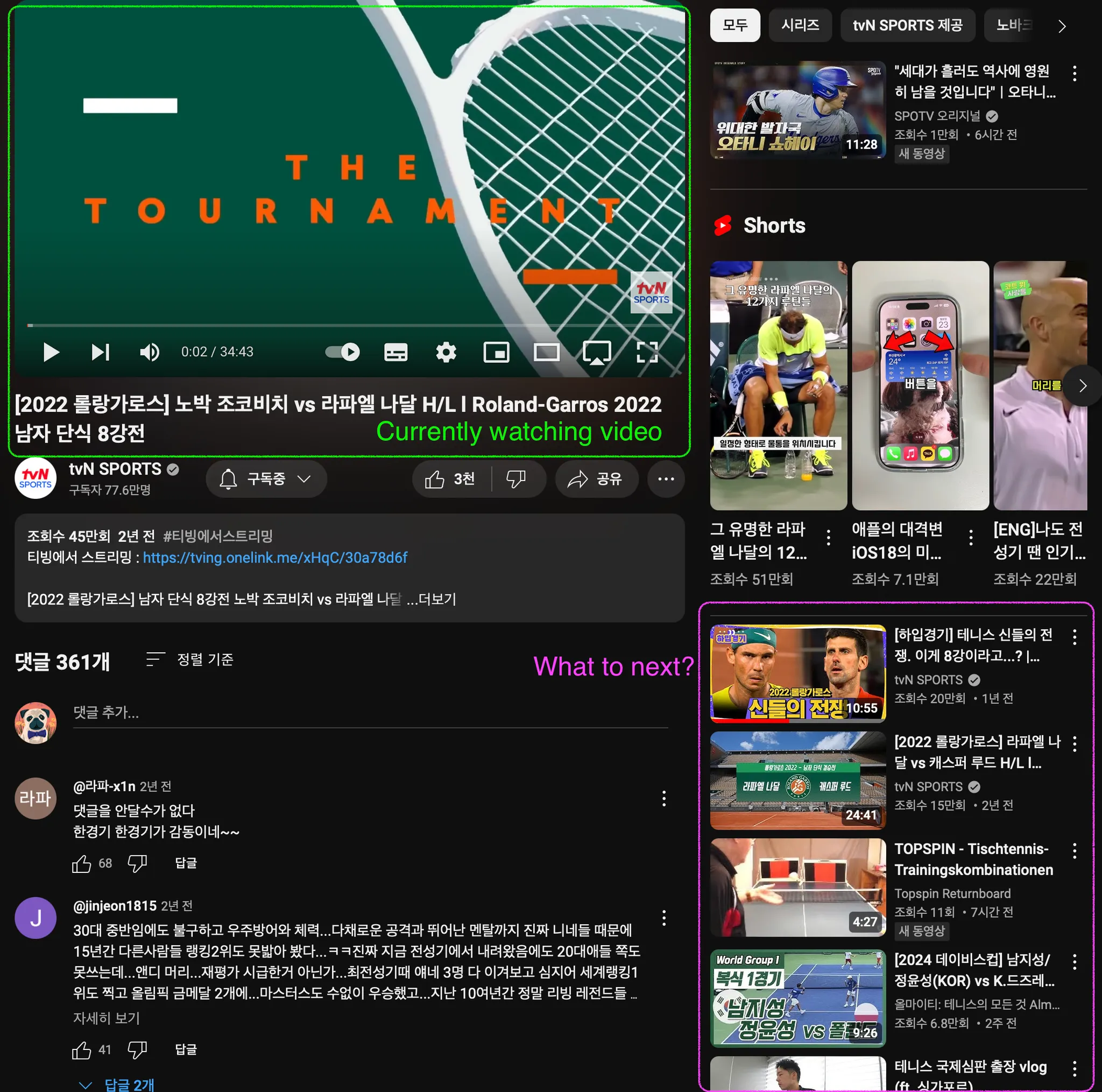
◦
위 그림을 한 번 봐볼게요. 현재 시청하고 있는 비디오는 테니스 경기입니다. 오른쪽 하단을 보면 사용자가 좋아할 것 같은 비디오를 추천해주는 걸 볼 수 있어요. 여기 있는 리스트를 어떻게 개인화 추천 해줄 수 있을 것인지가 이 논문에서 풀고 싶은 문제입니다.
◦
단순하게 생각하면, 간단하게 느껴질지도 모르겠습니다. 하지만 Youtube는 수십억 명의 사용자가 매일 수십억 개의 비디오를 올리기 때문에 수십억 개 중에 몇 개를 추천하는 시스템을 안정적으로 운영하는 것은 매우 힘든 일입니다.
◦
그래서 보통 2-stage로 나뉘어서 추천을 수행합니다. 아래는 마찬가지로 Google의 Youtube 논문에 나왔던 figure입니다.
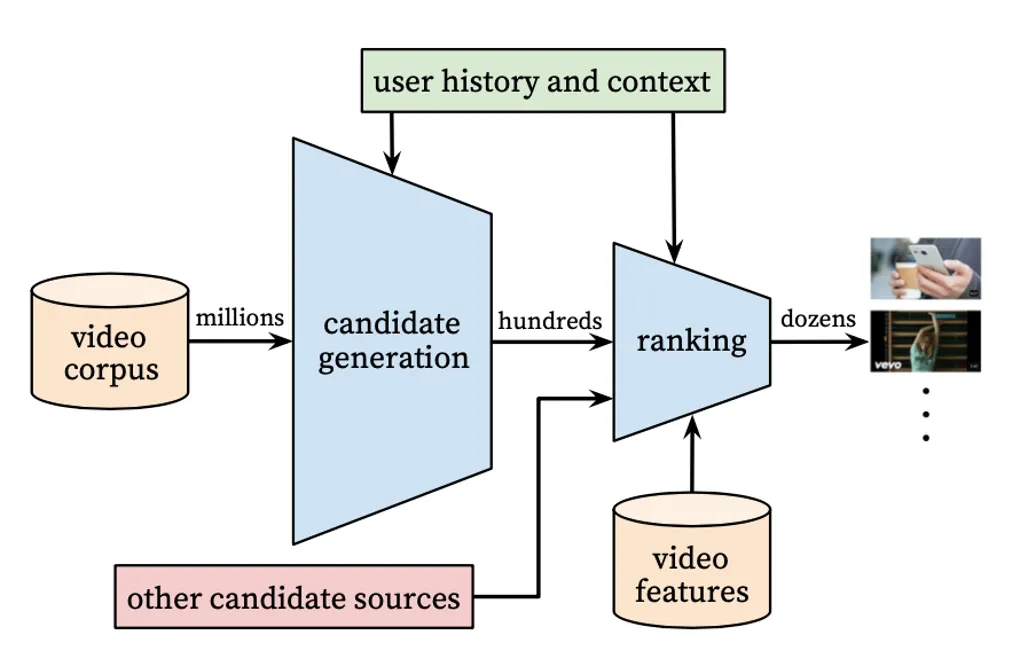
▪
candidate generation을 통해서 수백만개의 video를 수백 개로 줄이고, 뒤에서 더 정교하게 ranking을 매기게 됩니다. 이는 뒤에 한 번 더 소개되니, 대략적으로 알고 계시면 될 것 같습니다.
•
이런 large-scale의 recommendation 시스템을 product 환경에서 돌리기 위해서는 많은 challenging한 부분들이 존재합니다. 이 논문에서는 특히 아래 두 challenge를 해결하기 위해 노력합니다.
1.
Multi Objectives
•
추천 시스템의 목표가 여러 개가 있을 수 있습니다. 예를 들어 클릭을 많이 발생시키고, 좋아요가 많으면서 싫어요는 적게 받는 목표가 있을 수 있습니다.
•
각각의 목표는 유사하지만 동시에 학습시키는 과정에서 conflict가 발생할 수 있고, 모든 objective에 대해서 goal을 만족시키는 모델을 학습시키는 것은 쉽지 않습니다.
2.
Bias
•
추천 시스템은 bias와의 싸움이라고 해도 과언이 아닙니다. 모델을 학습시키기 위해서는 데이터가 필요한데, 이 데이터는 현재 시스템으로부터 생성된 데이터입니다. 그렇기 때문에 feedback loop가 발생하고 이런 걸로 인해 계속 같은 비디오만 추천된다던가 하는 문제가 발생할 수 있습니다.
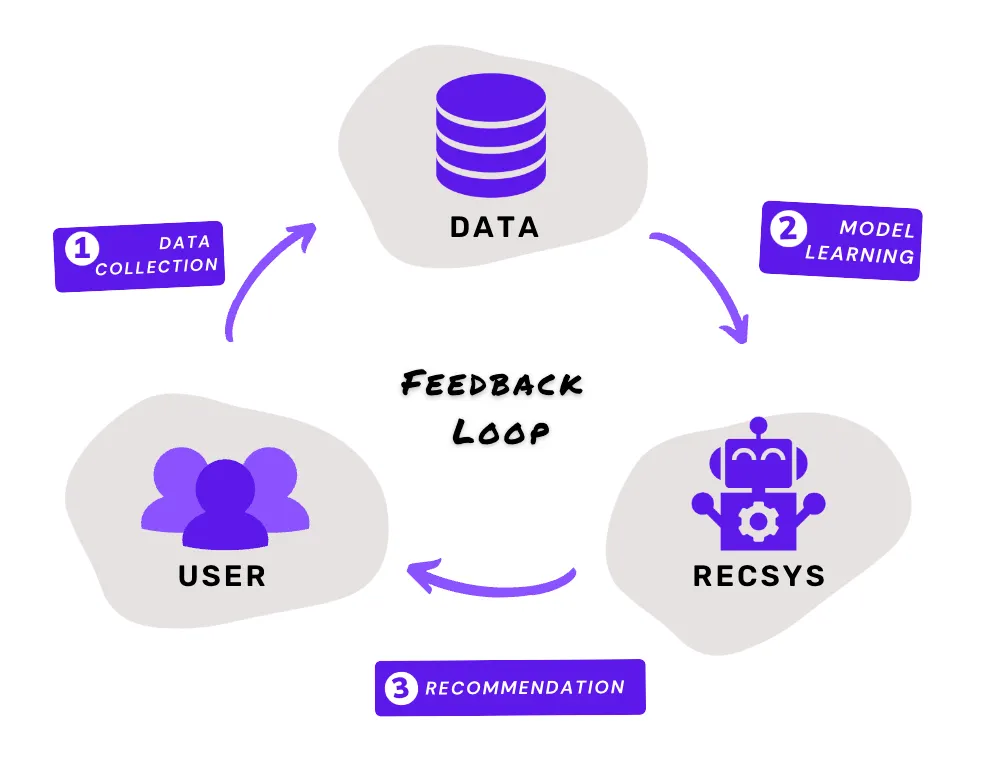
•
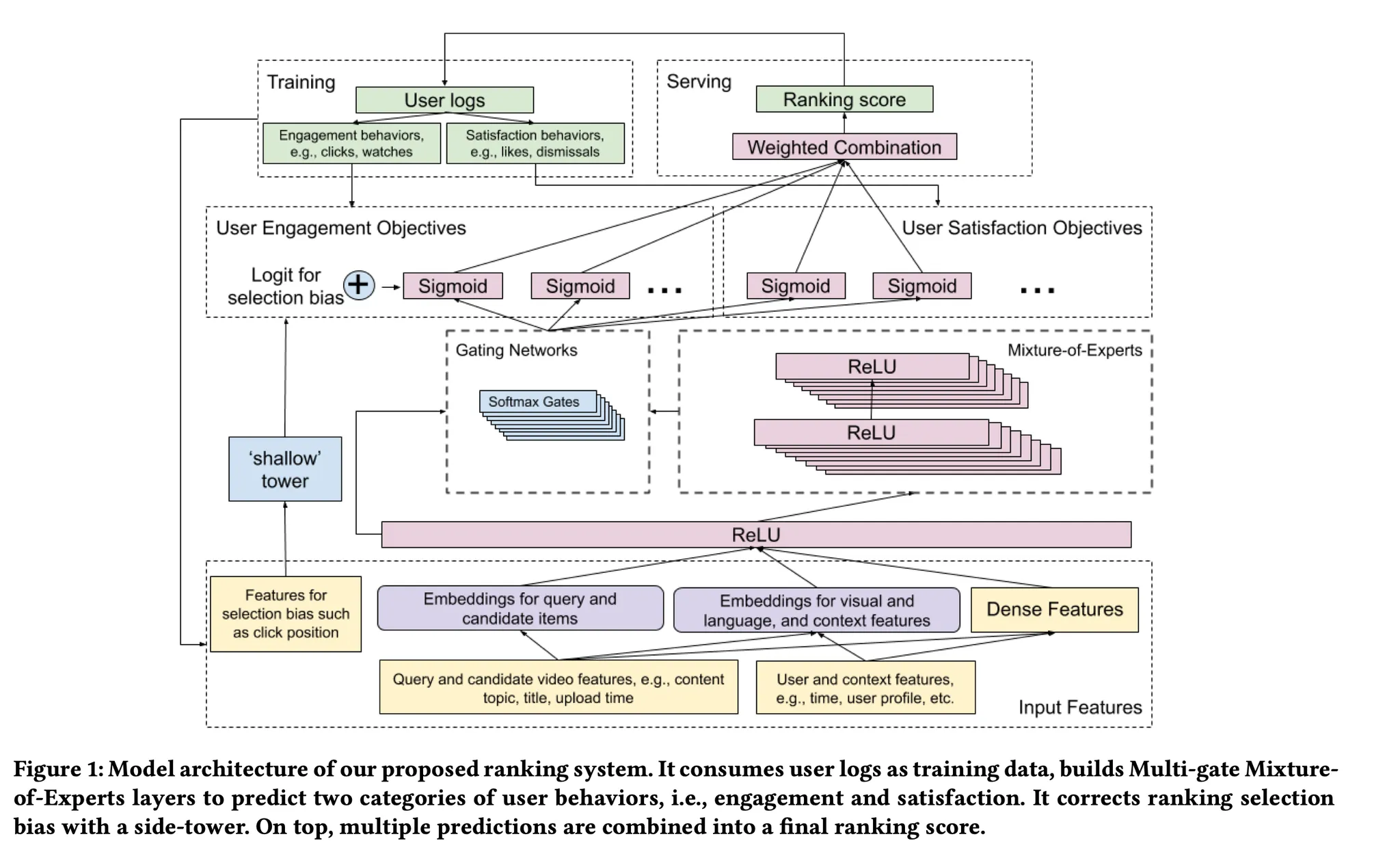
위 두 개의 챌린지를 해결하기 위해 이 논문은 MMoE구조를 채택하여 multi-objective를 강건하게 학습하면서도, shallow tower를 같이 학습시켜서 bias를 제거하고자했습니다.
•
이를 해결하기위한 모델 아키텍쳐는 아래와 같습니다.
◦
이해하기 어렵습니다 🫠. 아래에서 차근차근 한 component를 살펴보도록 하겠습니다.
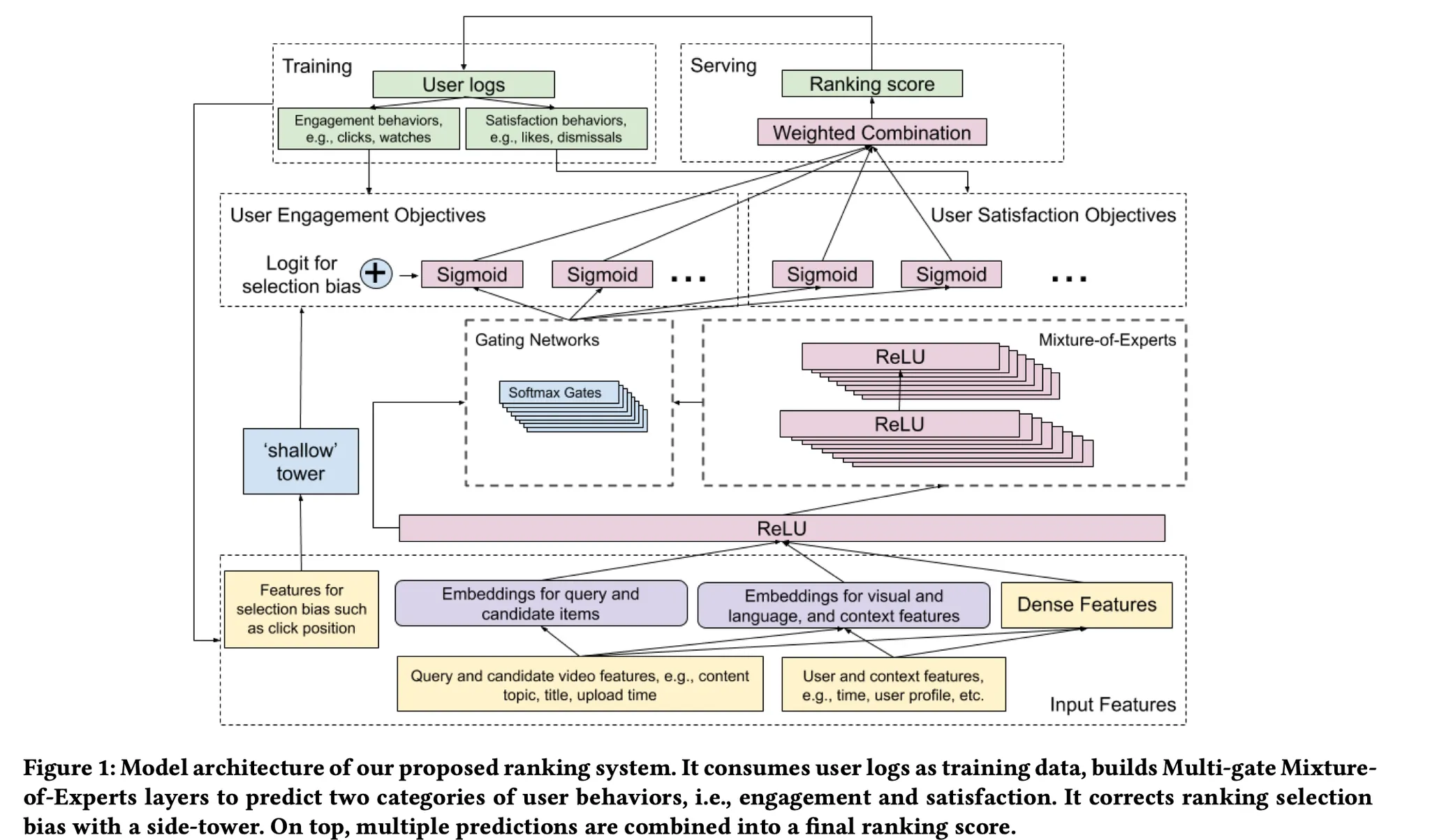
2. Related Work
•
Related work에서는 크게 3개의 sub-section으로 나뉩니다.
1.
Industrial Recommendation Systems
2.
Multi-objective Learning for recommendation Systems
3.
Understanding and Modeling Biases in Training Data
•
각각의 sub-section은 아래에서 중간중간 나올 예정이므로 생략합니다.
3. Problem Description
•
논문의 제목에서 알 수 있듯이 이 논문에서 저자들이 풀고자 하는 문제는 “현재 사용자에게 다음으로 볼 비디오를 추천하는 것”입니다. 이 섹션에서는 해당 문제가 가지는 챌린지들에 대해서 다시 한 번 설명하고, candidate generation과 ranking으로 구성되어있는 two-stage 구조에 대해 소개합니다. 이 논문은 이 둘 중에서 ranking 부분에 focus를 맞춥니다.
•
Real-World, 특히 유튜브와 같이 전세계 사람들이 사용하는 대규모 시스템에서 실시간으로 비디오를 추천한다는 것은 추가적으로 고려해야하는 요소들이 있습니다.
◦
Multimodal Feature Space
▪
상황을 이해하는 개인화 추천을 하기 위해서, 여러 modality(다양한 소스)로부터 후보 영상들의 user utility를 학습해야 합니다. 예를 들어서 Video Content 그 자체 내용이 될 수도 있고, thumbnail 이미지, audio, title, description, user demographics가 소스가 될 수 있습니다.
이 한 화면에도 다양한 소스의 데이터가 있는 것을 확인할 수 있습니다.
▪
이런 다양한 소스로부터 representation을 학습하는 것은 다른 ML 애플리케이션과 비교해서 유니크하게 가지는 challenging한 점들이 있습니다.
1.
Content Filtering
•
저자들은 여기서 *“semantic gap”*을 극복하는게 중요한 문제라고 하고 있습니다. 이는 low-level content feature(e.g., 섬네일 이미지, 비디오 제목 등)이 비디오의 종류, 사용자의 선호와 같은 고수준의 의미로 연결되어야 한다는 점에서 이런 용어를 사용한 것으로 보입니다.
2.
Collaborative Filtering
•
Collaborative Filtering은 추천에 관심이 있다면 다들 한 번쯤 들어보셨을 키워드입니다. 사용자와 아이템 간의 상호작용 데이터를 기반으로 추천하는 방식인데요.
•
여기서의 주요한 문제는 데이터가 sparse하다는 것입니다. 유튜브로 예를 들면, 사용자들이 모든 비디오를 보고 평가하지는 않기 때문에, 데이터가 매우 sparse하게 되고 이는 추천 모델을 학습하는데 있어서 챌린징한 부분입니다.
ref: sparse한 데이터의 예시
◦
Scalabiltiy
▪
말 그대로 확장성이죠. 수십억 명의 사용자가 사용하는 추천 시스템을 구축하기 위해서 확장성은 매우 중요합니다.
▪
추천 모델은 학습, 그리고 특히 서빙(즉, 추론) 측면에서 효율적이어야 합니다.
▪
이를 위해서, 추천 시스템을 두 단계로 나누게 됩니다.
•
바로 위에서 얘기가 몇 번 나왔던 Candidate Generation과 Ranking입니다.
3.1 Candidate Generation
•
유튜브에서는 다양한 candidate generation 알고리즘들을 가지고 있다고 합니다.
•
각각의 알고리즘들은 모두 쿼리 비디오(사용자가 시청 중인 비디오)와 candidate video의 유사성을 포착합니다.
◦
예를 들어서, 한 알고리즘은 쿼리 비디오와 유사한 토픽을 가지는 후보군을 생성합니다.
◦
또 다른 예로는, 쿼리 비디오와 함께 자주 시청된 비디오들로 후보군을 생성합니다.
우측 상단의 tab 하나하나가 ad candidate은 아닐까? 생각이 듭니다.
•
여기서 생성된 candidate video들은 ranking stage로 넘겨져서 디테일하게 스코어가 매겨집니다.
3.2 Ranking
•
Candidate generation 단계에서는 수백 개로 추려진 후보군들에 대해서 순위를 매기는 작업을 수행합니다.
•
Candidate generation 단계에서는 쿼리 비디오와 어떻게 유사한 비디오를 묶을까가 핵심이었다면, 해당 단계에서는 유저의 관심이 높을 것 같은 비디오를 상단에 위치시키기 위해서 스코어가 매겨진 리스트를 제공하는 것이 핵심입니다.
•
따라서 이 단계에서는 neural network와 같이 좀 더 advanced하고 복잡한 ML 기술들이 주로 사용됩니다.
4. Model Architecture
•
이 섹션에서는 논문에서 제안하는 ranking system에 대해서 자세히 설명합니다.
•
핵심은 아래 두 가지로 보입니다.
1.
Multi-task 학습을 통한 사용자 행동 예측
a.
MMoE라는 SOTA multi-task 학습 모델을 활용
2.
Selection(특히 position) bias를 어떻게 완화할 것인가
a.
Shallow tower를 MMoE 구조에 결합하여, training 데이터에서 발생하는 selection bias를 학습하고 감소시킴
4.1 System Overview
•
이 Ranking system에서는 두 가지 타입의 유저 반응을 예측하도록 학습합니다.
1.
Engagement Behaviors
•
click, watch와 같습니다. 이 행동을 한다고 사용자의 만족도가 높은 것은 아닙니다.
2.
Satisfaction Behaviors
•
like, dismissal와 같습니다. 사용자의 만족도를 직접적으로 알 수 있는 반응입니다.
•
첫번째 stage로부터 넘겨받은 candidate들로부터, ranking system은 다음과 같은 feature들을 활용하여 user가 어떤 행동을 할지를 예측하게 됩니다.
◦
Features of Candidate
▪
후보 비디오들의 특징이겠죠. 후보 비디오들의 카테고리, 섬네일 이미지, 제목 등이 될 수 있겠습니다.
◦
Query and Context
▪
현재 보고있는 비디오와 현재 user의 context(날씨, 시간 등)이 될 수 있겠습니다.
•
그러면 어떤 데이터를 가지고 학습한다는 것은 알았고, 모델링은 어떻게 할까요? 본 논문에서는 다양한 목적을 가지는 분류문제와 회귀문제의 조합으로 모델링합니다. 주어진 query, candidate, context를 가지고 ranking model은 사용자가 어떤 행동을 할지에 대한 확률을 예측하게 됩니다.
◦
이 방식은 point-wise approach 방식입니다. 추천에는 pair-wise, list-wise와 같은 다른 방식들도 존재하지만 추론시 효율을 위해서 point-wise 방식을 채택하고 있다고 합니다.
▪
간단히 말로 설명하자면, point-wise는 한 item에 대한 어떤 확률을 예측한다면, pair-wise나 list-wise는 item간의 순서도 고려하여 예측하는 방식입니다.
•
랭킹 성능이 pair나 list 방식이 더 좋겠지만, 모든 아이템들에 대한 고려를 해야하기 때문에 실시간 추론에는 적합하지 못합니다.
4.2 Ranking Objectives
•
위에서 여러 번 나왔듯이, 본 논문에서는 Ranking system이 여러 objective를 가지도록 설계했습니다. 설명의 편의성을 위해 밑에서는 2개의 objective(engagement, satisfaction objective)로 가정하고 설명합니다.
•
Engagement
◦
binary classification(i.e., clicks)
◦
regression (i.e., time spent)
•
Satisfaction
◦
binary (i.e., like)
◦
regression (i.e., rating)
4.3 Modeling Task Relations and Conflicts with Multi-gate Mixture-of-Experts
•
이 논문에서 푸는 문제가 multi-objective를 다루기 때문에, multi-objective를 다루는 모델 아키텍쳐에 대해서 고민을 했습니다.
•
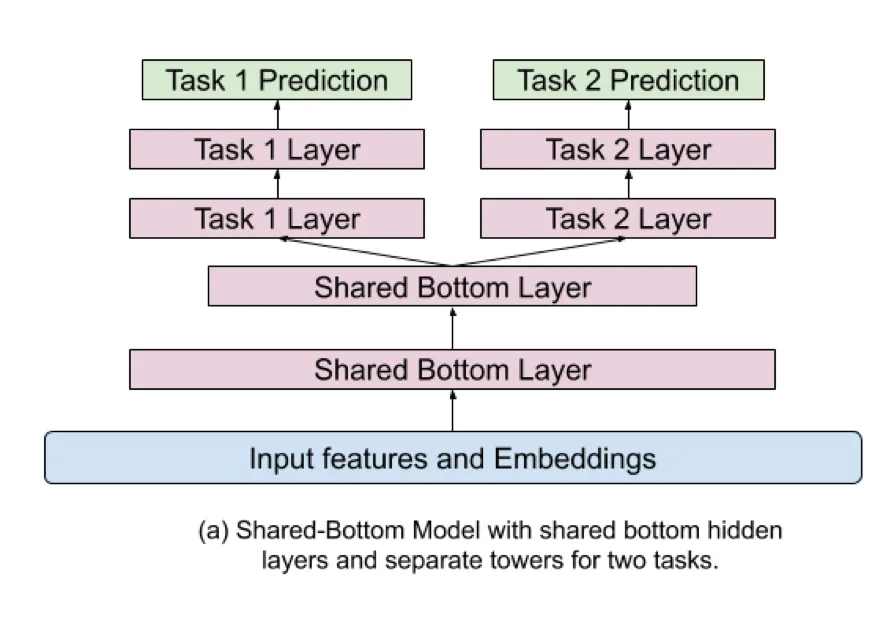
이런 ranking system에서는 shared-bottom model architecture를 흔히 사용하지만, task 간의 correlation이 낮다면 오히려 성능에 안좋은 영향을 줄 수 있습니다. 여러 objective를 같이 학습시키면서도 conflict를 완화하기 위해서, 해당 논문에서는 Multi-gate Mixture-of-Experts(MMoE) 아키텍쳐를 도입하고 확장했습니다.
•
MMoE는 soft-parameter sharing model구조로, task간의 conflict나 relation을 모델링하기 위해 디자인되었습니다. MMoE는 multitask 학습을 위해서 Mixture-of-Experts(MoE)구조를 따릅니다.
◦
MoE 구조를 글로만 설명하면 뭔말인가 싶을 수 있으니, 다른 아티클의 그림을 같이 보겠습니다. 논문에도 그림은 존재하는데요. 아래 그림이 더 직관적인 것 같아서 가져왔습니다.
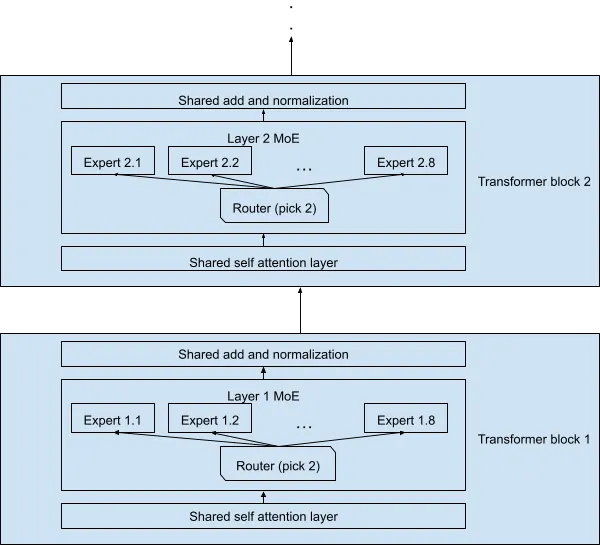
▪
MoE는 입력을 여러개의 experts 하위 네트워크로 분할하여 학습하는 신경망의 패턴입니다.
▪
그림에서 보다시피 각 transformer block에서 여러개의 experts가 존재하고, Router network를 통해서 어떤 experts layer를 사용할건지를 선택하게 됩니다.
•
추가로 설명을 덧붙이자면, 몇명의 experts를 사용할것인가는 학습 파라미터입니다.
•
예를들어 하나의 입력에 대해서 2개의 experts를 사용한다고 가정해보겠습니다. Router network는 보통 MLP인데, MLP를 통과해서 나온 outputs에서 logit이 가장 높은 2개를 선택하고 그 2개를 softmax layer를 태워서 각 experts의 가중치를 구하여 각 experts layer의 output에 고려되어 다음 layer로 전달되는 방식으로 구현됩니다.
•
이거를 수식으로 구현한 부분이 아래가 되겠습니다.
◦
Given task $k$, the prediction $y^k$, MMoE layer with n experts output for task $k$: $f^k(x)$
◦
$x$ is a hidden embedding, $g^k$ is the gating network for task $k$.
$$ y_k=h^k(f^k(x)), \\ where f^k(x)=\sum_{i=1}^{n}g_{(i)}^{k}(x)f_i(x) \\ g^k(x) = softmax(W_{g^k}x), $$
◦
여기서 MMoE가 MoE와 다른점은 task마다 gating network가 있다는 것입니다. MoE는 단일 gating network를 사용하여 주로 단일 작업을 처리하도록 설계되었습니다. 즉, 다른 task라도 같은 experts 가중치 조합을 가질 수 있습니다. 하지만 MMoE는 multi-objective학습에 적합하게 설계된 확장입니다. gating network가 task마다 있다는게 특징이구요. 그래서 각 task마다 최적의 experts 조합을 다르게 선택하여, 다른 작업들간의 특성을 더 잘 반영할 수 있게 됩니다.
◦
이런 MMoE 아키텍쳐를 사용함으로서 얻는 이점을 정리하자면 아래와 같겠습니다. (논문에 있는 내용은 아니고 제 생각입니다. )
)▪
각 task에 맞는 gating network를 학습하여, 개별 task의 특성에 맞게 experts를 선택 및 조합하는 방식으로 학습 효율을 높입니다. 이를 통해 서로 correlation이 없거나, conflict가 있는 task들로 인해 학습이 방해되는 것을 막을 수 있겠습니다.
4.4 Modeling and Removing Position and Selection Bias
•
보통 추천 시스템에서는 implicit feedback(e.g., click)을 학습에 많이 활용합니다(좋아요 나 싫어요 같은 explicit feedback은 너무 rare한 이벤트이기 때문입니다.). 하지만 이런 implicit feedback에는 “현재의 결과는 현재 존재하는 추천 시스템으로부터 생성되었다.” 라는 이유로 bias가 끼게 됩니다. 그에 대표적인 게 position, selection bias입니다.
나 싫어요 같은 explicit feedback은 너무 rare한 이벤트이기 때문입니다.). 하지만 이런 implicit feedback에는 “현재의 결과는 현재 존재하는 추천 시스템으로부터 생성되었다.” 라는 이유로 bias가 끼게 됩니다. 그에 대표적인 게 position, selection bias입니다.•
유튜브로 예를 들면, 보통 리스트의 가장 위에 있는 비디오가 주로 시청되고 클릭됩니다. User의 utility와는 상관없이 단순히 위에 있기 때문에, 클릭이 잘 되는 위치에 있기 때문에 클릭 되었다는 것입니다. 이런 데이터로 학습하면 모델은 bias가 낀 데이터를 학습하기 때문에 위험하겠죠.
◦
예를 들어, 한국의 평균 키를 구하는 문제를 푼다고 해보겠습니다. 그래서 군대에서 평균 키를 재었더니 174더라. 그래서 한국 사람의 키를 예측할 때 174로 예측하는 것과 비슷한 맥락이죠.
•
많은 추천시스템은 이런 bias를 없애기 위해 노력하고, 이 논문도 마찬가지입니다.
•
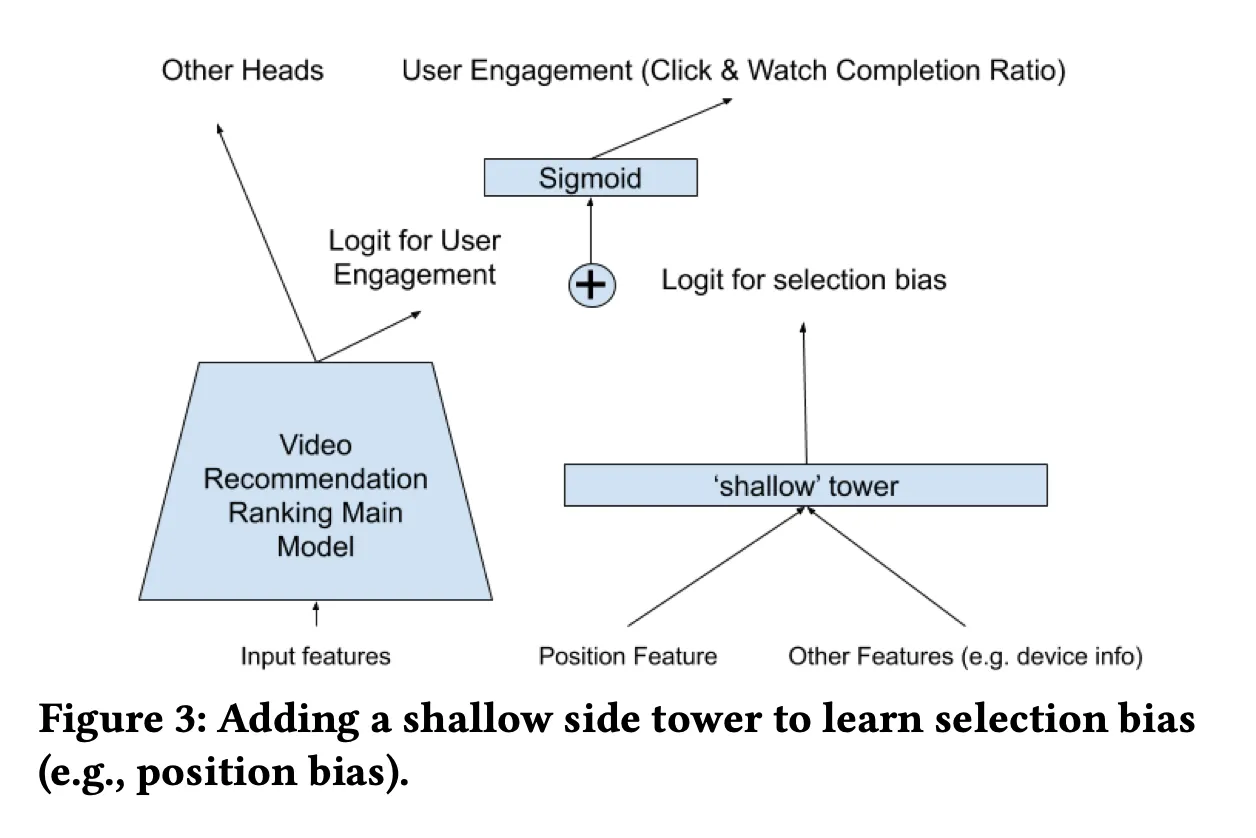
이를 위해 이 논문은 user-utility를 담당하는 main tower와 bias를 담당하는 shallow tower를 같이 학습합니다.
◦
shallow tower는 selection bias, position bias에 영향을 주는 feature들을 입력으로 받고, final logit이 main model의 final logit에 더해집니다.
◦
이러한 방식이 어떻게 bias를 없애는데 도움이 될까요?
▪
shallow tower는 위치정보를 바탕으로 해당 비디오가 클릭되거나 선택된 것에 대한 편향된 확률을 학습하고, 이를 main tower에 예측을 보정하는데 사용합니다.
▪
예를 들어서, 마지막에 있는 영상의 품질이 좋음에도 불구하고 단순히 위치 때문에 클릭 확률이 낮게 예측되었다고 합시다. 이 경우 shallow tower는 "마지막에 있어서 클릭이 덜 될 것"이라는 편향을 학습했고, 이를 기반으로 main tower의 낮은 예측값을 "위치 때문에 낮아졌을 뿐"이라고 보정할 수 있는 신호를 main tower에게 보내준다고 할 수 있겠습니다.
여기까지 와서 논문의 시작에 나왔던 아키텍쳐(Figure 1)를 다시 한 번 살펴보겠습니다. 이제는 각 컴포넌트가 이해가 가시죠?
5. Experiment Results
•
이 섹션에서는 Youtube 사용자의 implicit feedback을 사용해서 ranking 모델을 학습하여 offline, live(online이라고도 함)실험을 진행합니다.
◦
여기서 offline 실험이란, 모델 학습 후 AUC와 같은 metric을 살펴보는 걸 의미합니다.
◦
live(online) 실험이란, product에 랭킹시스템을 내보내서 얻을 수 있는 CTR, 좋아요 수 와 같은 metric을 살펴보는 걸 의미합니다.
•
이 당시에 유튜브의 MAU(monthly active user)는 19억 명 정도 되고, 매일 수천억 건의 사용자 로그를 생성해냈다고 합니다.
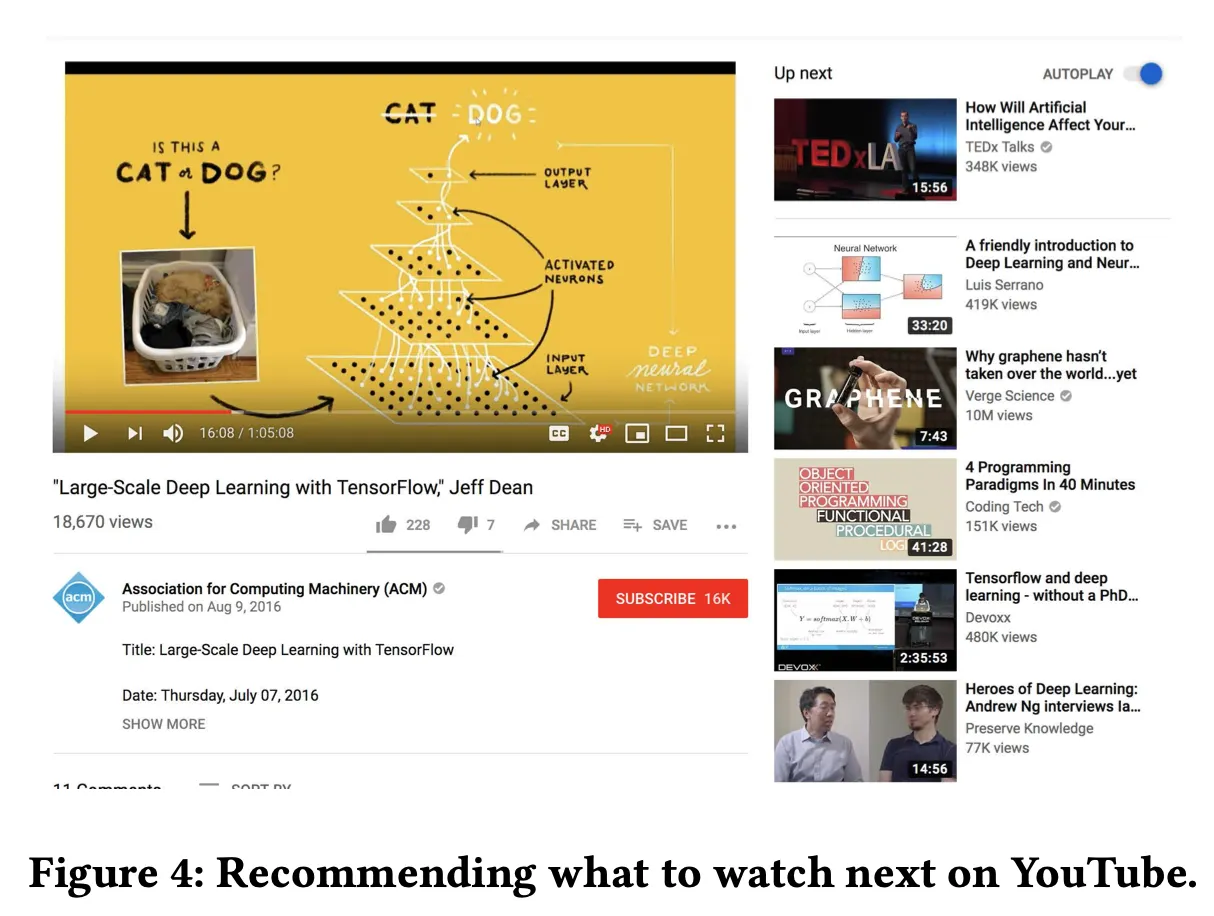
◦
이 랭킹 시스템은 아래 사진에서 오른쪽에 보이는 Up next 리스트를 추천해주는 것으로 보입니다.
5.1 Experiment Setup
•
모델 학습과 서빙은 Tensorflow 사용. 구체적으로는 TPU를 사용해 모델을 학습하고, TFX를 사용해 모델을 서빙했다고 합니다.
•
Offline 실험에서는 AUC(for classification task), Squared Error(for regression)을 모니터링했고, live에서는 유튜브에 머무른 시간, 좋아요 등을 관찰했습니다.
•
또한 live metrics에서는 모델 서빙 시에 computation cost도 같이 신경썼다고 합니다.
5.2 Multitask Ranking with MMoE
•
Multitask ranking을 위해서 도입한 MMoE의 성능을 평가하기 위해서 baseline methods와 같이 live 실험을 수행했습니다.
•
베이스라인 모델은 shared-bottom model 아키텍쳐를 구성했습니다.
•
반대로 MMoE 구조는 아래와 같습니다.
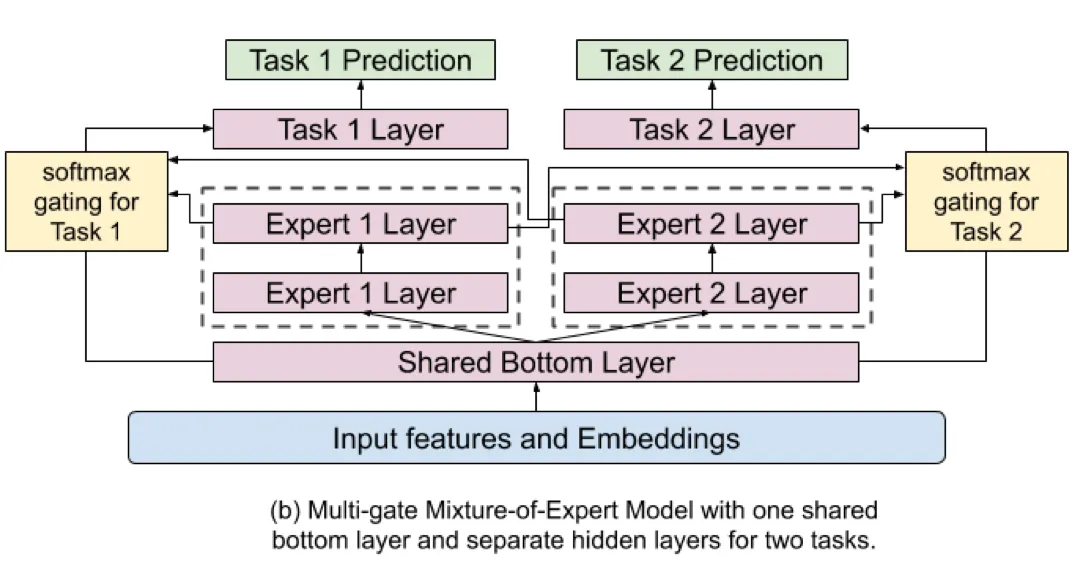
•
실험 결과는 이렇습니다.

◦
Multiplication 수로 computation cost를 유추하는 것으로 보입니다. MMoE도 shared bottom layer를 하나 가지기 때문에 computation cost에는 별 차이가 나지 않는 것을 확인할 수 있습니다.
◦
또한 MMoE를 썼을 때, live metric의 성능이 오르는 것을 확인할 수 있고 experts가 8개일 때 더 높은 성능을 보여주는 것을 확인할 수 있습니다.
•
MMoE가 multi-objective optimization에 어떻게 도움을 주는지 더 이해하기 위해서, 각 task에 대하여 softmax gating network의 확률을 plot해주었습니다.
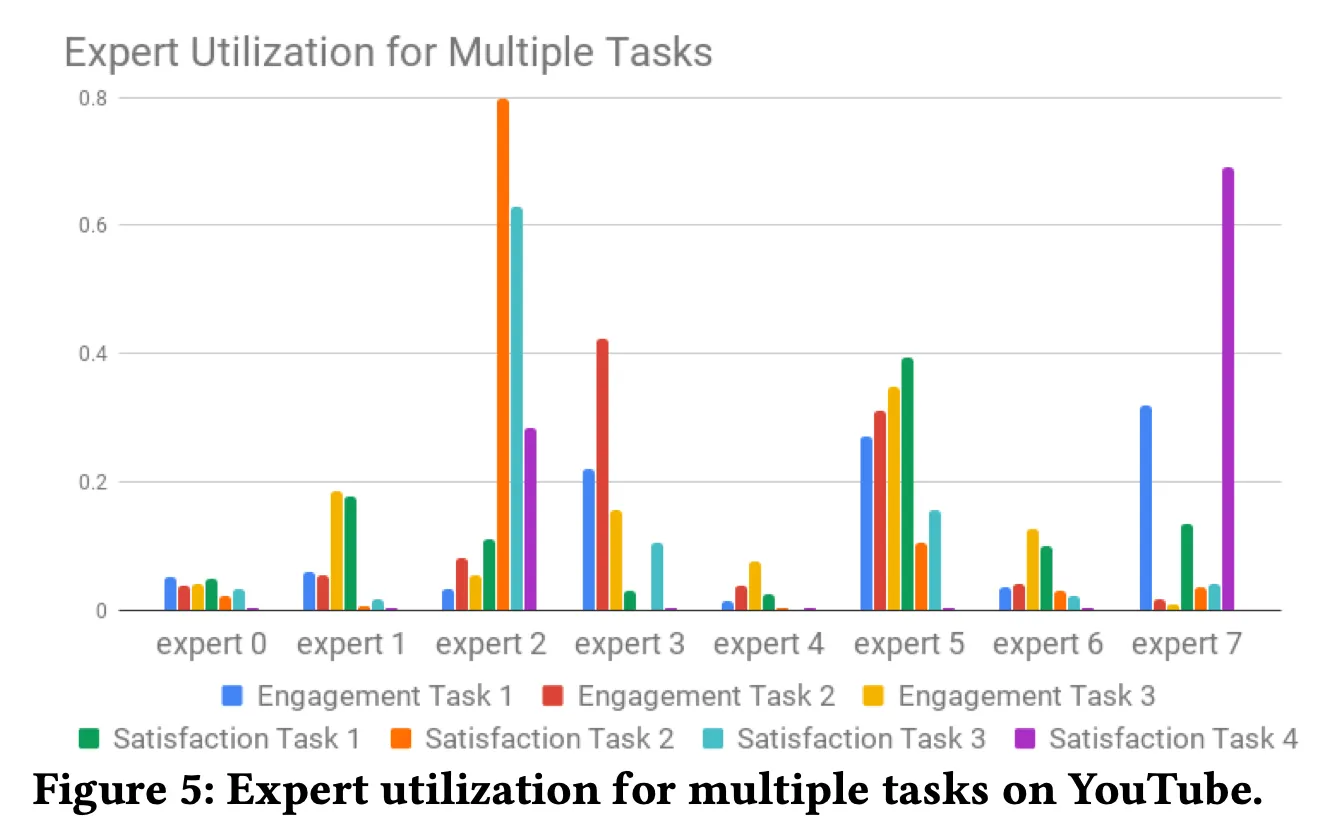
◦
figure를 보면, 한 task에 대해 여러 experts들이 관여하는 것을 확인할 수 있습니다. 한 task에 대하여 correlation이 높은 여러 expert들이 관여하여 더 높은 성능을 내는 것이 아닌가 생각이 됩니다.
◦
또한 세세한 내용으로 Gating network를 학습할 때, 양극화되어서 expert의 distribution이 너무 imbalance한 문제가 있었다고 하는데요, gating network에 dropout을 배치해서 이를 해결했다고 합니다.
5.3 Modeling and Reducing Position Bias
•
Position Bias
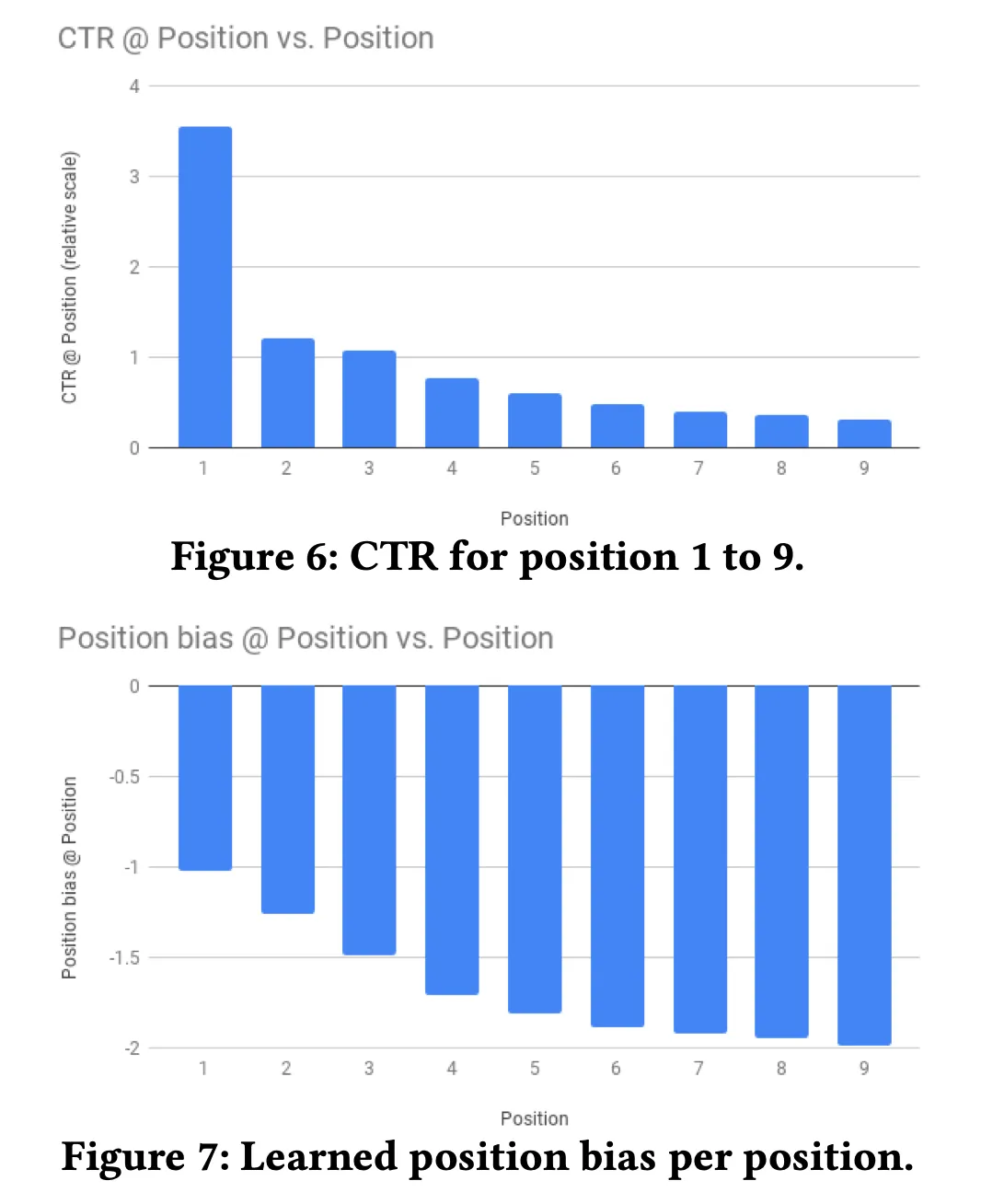
◦
figure 6를 보면, position 별로 CTR이 얼마나 다른 지를 보여줍니다.
◦
figure 7을 보면, 학습된 position bias를 보여주는데요. 이게 main tower의 final logit에 더해져서 학습 시에 실제 예측값을 보정해줄 수 있겠습니다.
◦
실제 서빙 시에는 position을 missing value로 넣어서, position bias가 없는 예측을 활용한다고 하네요.
•
Shallow tower와 비교하기 위해서, Domain adaptation의 adversarial loss를 같이 보여주고 있는데요. Shallow tower의 성능이 더 좋습니다.
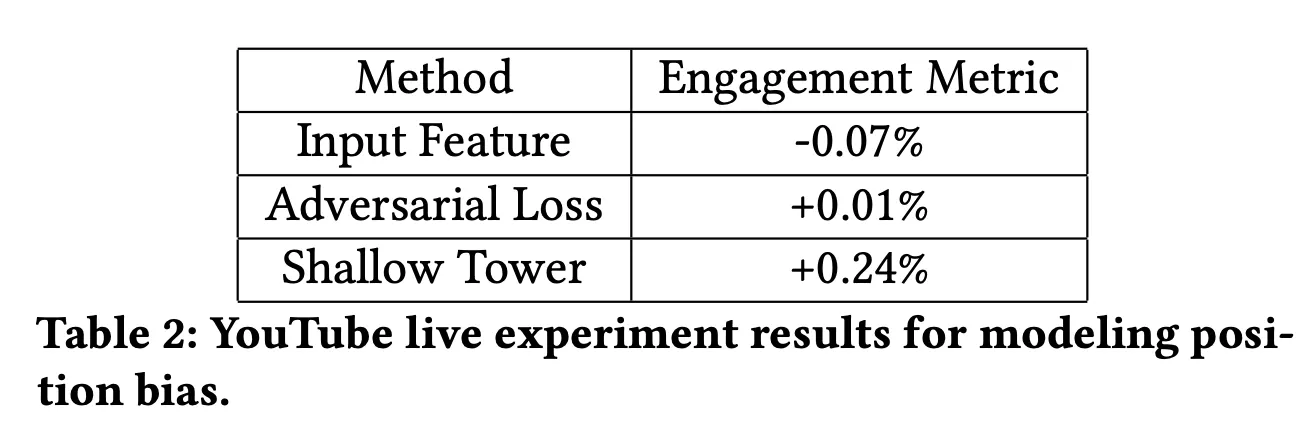
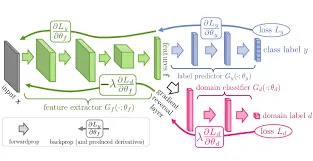
5.4 Discussion
•
이 섹션에서는 이 랭킹시스템을 만들면서 얻은 insights와 limitation들을 말해줍니다.
1.
Neural Network Model Architecture for Recommendation and Ranking
•
추천시스템에서 사용되는 모델이 computer vsision이나, NLP와 같은 task에서 사용되는 아키텍쳐를 사용하지만, 아래와 같은 이유들로 적합한 구조는 아니라고 합니다.
◦
multimodal feature spaces
▪
natural language나 image 문제와는 다르게 추천은 여러 소스로부터의 feature에 의존하게 됩니다. 여러 feature space로부터 학습하는 것이 challenging하다고 합니다.
◦
scalability and multiple ranking objectives
▪
보통은 하나의 objective를 가지지만, 추천은 여러 objective를 가집니다. 그러면서도 확장성있는 구조까지 생각해야 합니다.
◦
Noisy and locally sparse training data
▪
training data가 long-tail 형태로 생겼고, 그런 item들에 대해서는 학습이 어렵습니다.
◦
Distributed training with mini-batch SGD
▪
큰 neural network를 사용하기 때문에, 분산 학습을 해야 하는데 이것 자체로 어렵습니다.
2.
Tradeoff between Effectiveness and Efficiency
•
성능이 좋은 모델을 만들기 위해서는 cost가 비싸지고, cost를 아끼자니 성능이 떨어집니다.
3.
Biases in Training Data
•
이 논문에서 다루는 position bias이외에도 여러 타입의 bias들이 존재하는데, 그것을 어떻게 자동으로 찾고, 모델링할지가 어렵습니다.
4.
Evaluation Challenge
•
offline지표와 online지표가 align되지 않아 어렵습니다.
마지막으로 아래와 같은 방향을 future direction으로 말하면서 끝납니다.
•
모델 performance를 해치지 않으면서도, 성능이 좋은 multi-objective ranking을 위한 모델 아키텍쳐에 대한 연구
•
알지 못하는 bias들을 자동으로 찾고 모델링하여서 bias를 완화할 수 있는 아키텍쳐
•
서빙 비용을 줄이기 위한 모델 압축
참고자료
작성자
관련된 글 더 보기















