


안녕하세요. 데이블 AI팀 엔지니어링 파트에서 일하고 있는 강천성입니다. 
이번 글에서는 제가 사이드 프로젝트로 만들고 있는 “나만의 작은 Chezipsa v2”에 대해 이야기해보려고 합니다.
이 프로젝트는 2025 AI Hackathon에서 3등을 수상했던 채집사(Chezipsa) 프로젝트를, 실제 사내 환경에 맞게 확장·재구성한 버전입니다.
데이블에는 오랜 기간 운영되어 온 다양한 사내 페이지들이 있습니다.
예를 들면
•
광고 운영을 위한 admin 페이지
•
내부 운영 툴들이 모여 있는 hq 페이지
•
마케팅 관련 작업을 위한 marketing 페이지
이 페이지들은 시간이 지나면서 기능이 추가·수정되고, 담당자가 바뀌거나 팀이 개편되면서 “코드는 어딨고, 누가 알지…?” 라는 순간이 점점 더 자주 등장하게 됐습니다.
•
“이 버튼 눌렀을 때 정확히 어떤 API가 호출되지?”
•
“예전에 만들었다는 보정 로직이 있는데, 지금도 동작하는 게 맞나?”
•
“담당자가 퇴사해서 물어볼 사람도 없는데, 일단 코드를 뒤져볼까요…?”
결국 크게 복잡하지 않은 로직임에도 개발자의 시간을 계속 쓰게 되는 구조였습니다.
이 불편함을 줄여보고 싶었습니다.
그래서 시작한 것이 Chezipsa v2입니다.
목표는 아주 단순합니다.
“사내 페이지의 스크린샷 한 장과 간단한 질문만 주면,
에이전트가 알아서 코드베이스를 탐색하고
‘어디에서, 어떤 코드로, 어떻게 동작하는지’를 설명해주는 것.”
이번 글에서는 Chezipsa v2를 만들게 된 배경과 요구사항,
그리고 이를 구현하기 위해 설계한 아키텍처·인프라·에이전트 구조를 공유해보려고 합니다.
1. 왜 이런 도구가 필요했을까? – Needs
Chezipsa v2를 만들기로 마음먹게 된 이유는 크게 세 가지였습니다.
1) 담당자가 사라진 기능들
시간이 지나면 서비스는 자연스럽게 복잡해지고, 사람은 이동하거나 퇴사합니다.
특히 사내에서만 사용하는 admin / hq 계열 페이지의 경우
•
초기에 한 명이 빠르게 구현하고
•
이후 여러 사람이 조금씩 붙여넣듯 기능을 쌓아 올리고
•
어느 순간 “지금은 아무도 전체 맥락을 모른다” 상태가 되기 쉽습니다.
이런 기능에 대해 문의가 들어오면 결국 “일단 코드부터 찾아보자”가 기본 대응이 됩니다.
작은 수정 한 번, 정책 확인 한 번 할 때마다 개발자의 컨텍스트 스위칭이 발생하죠.
2) 단순하지만 설명하기 까다로운 로직
반대로 로직 자체는 복잡하지 않은데,
어느 파일에서 시작해서 어디까지 이어지는지 파악하기까지 시간이 꽤 걸리는 경우도 있습니다.
•
React 컴포넌트 → 공통 훅 → API 클라이언트 → BFF → 마이크로서비스
•
중간에 feature flag나 실험 코드가 끼어 있는 경우
•
설정이 여러 레이어에 흩어져 있는 경우
이런 “코드 따라가기” 작업은 누구나 할 수 있지만,
매번 새로 들어가는 시간은 결코 작지 않습니다.
3) 문의 대응에 드는 리소스
기획/운영/CS에서 들어오는 질문 중에는
“코드를 읽으면 바로 답이 나오지만, 해당 레포·도메인을 아는 사람이 아니면 보기 어렵다” 류의 것들이 있습니다.
•
특정 필터가 어떤 조건으로 동작하는지
•
특정 숫자가 어떤 로직으로 계산되는지
•
버튼/토글이 실제로 어떤 상태를 변경하는지
이런 질문 때문에 매번 개발자를 호출하는 대신,
“UI 스크린샷 + 간단한 질문 → 설명 텍스트” 정도까지만 자동화할 수 있어도
팀 전체의 피로도가 꽤 줄어들 수 있겠다는 생각이 들었습니다.
2. Chezipsa v2의 목표와 요구사항
위와 같은 문제들을 해결하기 위해 Chezipsa v2에 다음과 같은 요구사항을 잡았습니다.
기능적 요구사항
1.
스크린샷 + 현재 페이지 URL만으로 질의가 가능할 것
•
사용자는 별도의 설명 없이도 “여기 영역이 궁금하다” 정도만 표시하면 됨
2.
여러 코드베이스를 자동으로 구분할 것
•
admin.dable.io, hq.dable.io, marketing.dable.io 등
•
도메인/URL만 보고 어느 레포를 뒤져야 할지 스스로 판단
3.
프론트엔드에서 백엔드까지의 흐름을 추적할 것
•
해당 UI를 렌더링하는 컴포넌트
•
클릭 시 호출되는 API
•
API 뒤에 있는 서비스/핵심 로직
4.
사람이 읽을 수 있는 형태로 요약해 줄 것
•
“이 버튼은 ○○ API를 호출해 △△ 값을 업데이트합니다.” 수준의 설명
•
비개발자도 읽을 수 있지만, 개발자에게도 충분히 유용한 밀도
비기능적 요구사항
1.
기존 코드베이스를 변경하지 않을 것
•
분석을 위해 별도의 SDK를 심거나 로깅을 추가하지 않고,
•
“코드를 읽기만 하는 도구”로 동작
2.
레포의 최신 상태를 어느 정도 보장할 것
•
GitHub에서 정기적으로 코드 스냅샷을 가져와 분석에 사용
3.
응답 속도는 “대화형”에 가깝게
•
사람에게 직접 물어보는 것보다는 빠르게,
•
다만 정밀 분석이 필요한 경우에는 느려도 괜찮도록 옵션 제공
3. High-level Design – Chezipsa v2는 어떻게 동작하나?
위 요구사항을 기반으로, Chezipsa v2의 전체 흐름을 다음과 같이 설계했습니다.
1.
사용자가 크롬 익스텐션으로 현재 보고 있는 페이지의 영역을 캡처합니다.
2.
익스텐션이 스크린샷 + 현재 URL + 간단한 프롬프트를 Chezipsa 서버로 전송합니다.
3.
Chezipsa 서버의 에이전트가
•
어느 레포를 볼지 결정하고(Find Repo)
•
스크린샷에서 어떤 기능인지 이해한 뒤(Image Analysis)
•
실제 코드베이스를 탐색합니다(Code Analysis).
4.
최종적으로 추출된 정보를 정리해,
•
“어떤 파일에서 시작해 어디까지 이어지는지”
•
“어떤 비즈니스 로직을 수행하는지”
를 자연어로 설명합니다.
아래 다이어그램은 Chezipsa v2의 코어 아키텍처를 표현한 그림입니다.
(그림 1) Chezipsa v2 Core Architecture
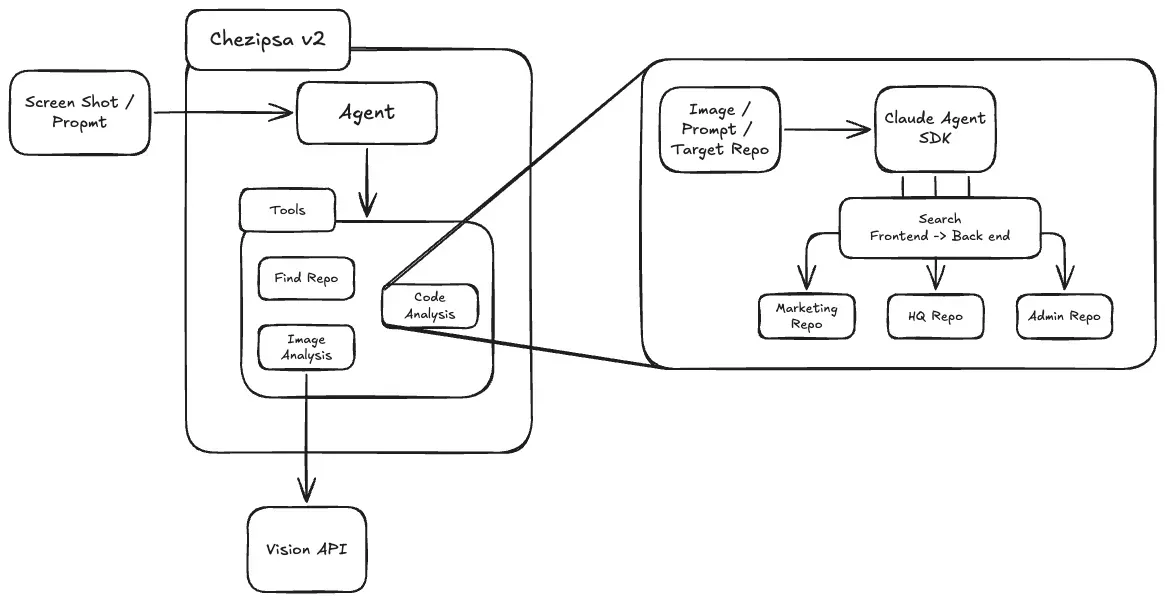
•
Screen Shot/Prompt → Agent → Tools(Find Repo / Image Analysis / Code Analysis) → Claude Agent SDK → 각 레포 검색, Vision API 연동
이 다이어그램에서 중요한 포인트는:
•
Agent 레이어는 전체 흐름을 orchestration 하는 두뇌 역할을 하고,
•
Tools 블록 아래에 Find Repo / Image Analysis / Code Analysis가
각각 독립적인 기능으로 배치되어 있으며,
•
Code Analysis는 Claude Agent SDK와 통신하면서
◦
프론트엔드에서 백엔드로 이어지는 검색(Search Frontend → Backend)을 수행한다는 점입니다.
아래에서 각 컴포넌트를 조금 더 자세히 살펴보겠습니다.
4. Chezipsa v2 에이전트 구성
4.1 Agent & Tools
Chezipsa v2의 에이전트는 PydanticAI 기반으로 구현되어 있고,
내부적으로는 다음 세 가지 도구를 사용합니다.
① Find Repo
•
입력: 현재 페이지 URL / 도메인
•
출력: 탐색해야 할 GitHub 레포 정보
◦
예: admin.dable.io → dable-admin-web 레포
•
규칙 기반 매핑 + LLM 보조를 함께 사용해,
새로운 서브도메인이 추가돼도 비교적 쉽게 확장할 수 있도록 설계했습니다.
② Image Analysis
•
입력: 스크린샷 이미지, 선택된 영역(또는 전체 화면), 필요 시 HTML 스냅샷
•
동작:
◦
Vision 모델(ChatGPT, Gemini, Claude 등)을 호출해
“이 화면에서 어떤 기능을 보고 있는지”를 요약
◦
버튼 라벨, 인풋 필드의 placeholder, 주변 텍스트 등을 추출
•
출력 예:
◦
“캠페인 수정 모달에서 ‘저장’ 버튼을 클릭했을 때 동작을 물어보고 있음”
◦
“좌측 필터 영역에서 ‘노출 제한’ 옵션 관련 로직이 궁금한 상황”
이 결과는 Code Analysis 단계에서 프롬프트의 핵심 단서로 사용됩니다.
③ Code Analysis
•
입력:
◦
Image Analysis 결과(기능 설명)
◦
유저 프롬프트
◦
타겟 레포 정보
•
동작:
1.
Vision 분석 결과와 유사한 이름/텍스트를 가진 컴포넌트를 레포에서 검색
2.
해당 컴포넌트에서 사용하는 핸들러/훅/스토어를 따라가며 로직의 시작점을 식별
3.
네트워크 호출, API 클라이언트, BFF, 백엔드 서비스 코드를 순차적으로 추적
4.
주요 분기/예외 처리/데이터 플로우를 정리하고 요약
•
모델:
◦
기본 모드: Claude 4.5 Sonnet (정밀 분석, “자세하게”)
◦
경량 모드: Claude Haiku (속도 우선, “빠르게”)
사용자에게는 단순히 “빠르게(Haiku)” vs “자세하게(Sonnet)” 옵션만 보여주고,
어떤 모델을 쓸지는 내부에서 매핑하도록 설계했습니다.
5. Infra & Deployment – 코드와 에이전트는 어디서 만나는가?
에이전트만 잘 만들어서는 실제로 코드를 분석할 수 없습니다.
Chezipsa v2는 GitHub, AWS 인프라, Chrome Extension을 엮어 “코드 스냅샷 + 에이전트” 구조를 만들었습니다.
아래 다이어그램은 전체 인프라 구성을 요약한 그림입니다.
(그림 2) Chezipsa v2 Infra & Deployment
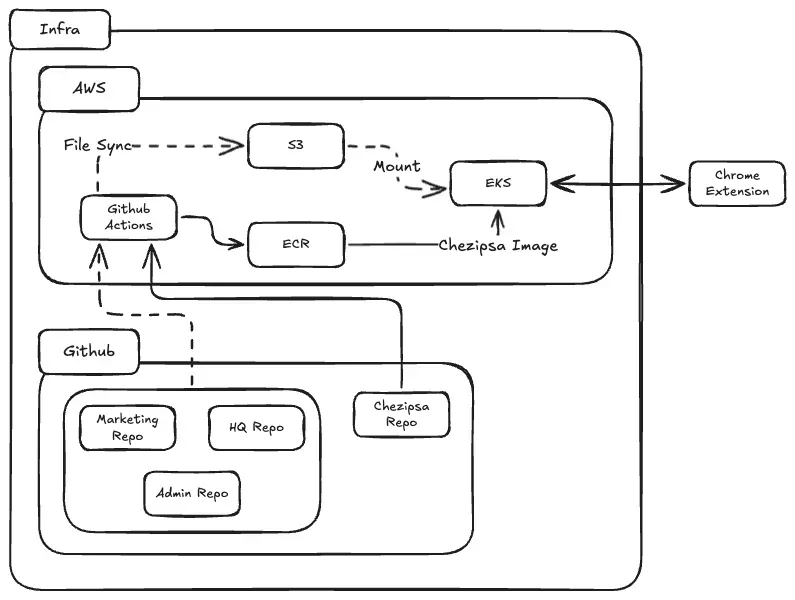
•
GitHub Repos → GitHub Actions → S3 / ECR → EKS(서비스) → Chrome Extension
5.1 GitHub & File Sync
•
Marketing Repo, HQ Repo, Admin Repo와 같은 서비스 레포는 GitHub에 호스팅되어 있습니다.
•
GitHub Actions를 사용해 정기적으로 코드 스냅샷을 생성하고, 이를 S3 버킷에 업로드합니다.
•
Chezipsa 레포 역시 GitHub에 존재하며, 서버 배포 시 Docker 이미지 빌드 후 ECR에 컨테이너 이미지로 올라갑니다.
이 구조를 통해
•
운영 환경의 코드와 Chezipsa가 보는 코드 사이의 시차를 최소화하고,
◦
main 에 반영된 코드가 즉시 프로덕션에 배포되지 않을 수 있기 때문에 약간의 지연이 발생할 수 있습니다.
•
레포가 늘어나더라도 File Sync 설정만 추가하면 바로 대상에 포함할 수 있습니다.
5.2 AWS: S3, ECR, EKS
•
S3
◦
각 레포의 코드 스냅샷이 저장되는 곳
◦
Chezipsa 서버는 이 스냅샷을 마운트(or 다운로드)하여 정적 코드베이스로 사용
•
ECR
◦
Chezipsa 서버 이미지를 저장
•
EKS
◦
Chezipsa 서버가 실제로 동작하는 쿠버네티스 클러스터
◦
S3에 저장된 코드 스냅샷을 볼륨 형태로 연결해
Code Analysis 단계에서 자유롭게 탐색할 수 있도록 구성
다이어그램에서는 S3 → EKS Mount를 점선으로 표현했는데, 실제로는 “에이전트가 읽을 수 있는 파일 시스템”으로 노출시킵니다.
5.3 Chrome Extension
마지막으로, 실제 사용자가 마주하는 엔트리 포인트는 Chrome Extension입니다.
•
사용자는 크롬 브라우저에서 사내 페이지를 보다가 “여기 로직이 궁금한데?” 싶으면 익스텐션을 클릭합니다.
•
마우스로 특정 영역을 마우스를 올려 영역을 캡처하고, 텍스트로 간단한 질문을 입력합니다.
•
익스텐션은 다음과 같은 로직을 수행합니다.
◦
스크린샷 이미지를 업로드 엔드포인트로 먼저 보내고(file id 획득)
◦
URL, file id, 프롬프트를 분석 요청 엔드포인트로 전송합니다.
•
서버에서는 이미지·file id 유무를 보고 업로드가 끝나기를 기다리거나, 이미 저장된 이미지를 로딩하는 식으로 UX를 매끄럽게 처리합니다.
6. 구현 상세 – 에이전트를 실제로 움직이게 만든 기술들
6.1 Web Framework & Agent Stack
Chezipsa v2의 서버는 다음 스택을 기반으로 구현하고 있습니다.
•
Python Web Framework: Starlette
◦
비동기 지원, 가벼운 라우팅, 간단한 미들웨어 구성이 장점
•
Agent Framework: PydanticAI
◦
툴 정의, 입력·출력 스키마 관리에 사용
•
LLM Client
◦
OpenAI Interface (Vision & 경량 모델)
◦
Claude Client SDK (Sonnet / Haiku)
에이전트 로직은 PydanticAI가 관리하고, 실제 모델 호출 부분만 OpenAI/Claude 클라이언트로 분리해 두어 향후 모델 교체를 유연하게 할 수 있도록 구성했습니다.
6.2 UX를 위한 비동기 이미지 업로드
이미지 기반 분석은 필수지만, 업로드가 느리면 UX가 크게 망가집니다.
그래서 요청 흐름을 다음과 같이 분리했습니다.
1.
이미지 업로드 엔드포인트
•
브라우저에서 영역 캡처 후 가장 먼저 호출
•
업로드가 완료되면 file_id를 반환
2.
분석 요청 엔드포인트
•
유저가 “전송” 버튼을 눌렀을 때 호출
•
이 시점에는 이미지 binary(base64)가 직접 붙어서 오거나 이미 받아둔 file_id만 전달될 수 있음
서버에서는 두 경우를 모두 처리할 수 있도록 설계했습니다.
•
이미지가 함께 오면 저장 후 file_id 할당
•
file_id만 오면, 이미 저장된 이미지를 찾아 사용
이렇게 해두면, 네트워크 상태에 따라 업로드가 조금 늦어져도
사용자 입장에서는 “이미 전송을 눌렀다”는 느낌을 먼저 줄 수 있습니다.
6.3 Find Repo & Image Analysis의 병렬 실행
Find Repo와 Image Analysis는 서로 의존성이 없습니다.
•
Find Repo는 URL 문자열만 필요하고,
•
Image Analysis는 이미지 + HTML만 있으면 됩니다.
따라서 에이전트 레벨에서 이 둘을 병렬로 실행하도록 구성했습니다.
이렇게 하면 전체 응답 시간에서 의미 있는 몇 초를 줄일 수 있습니다.
이후 Code Analysis 단계에서:
•
Find Repo 결과로 어느 레포를 뒤질지가 정해지고,
•
Image Analysis 결과로 어떤 기능을 찾아야 할지가 정해진 상태에서
본격적인 코드 탐색이 시작됩니다.
7. 지금까지의 인사이트와 앞으로의 계획
Chezipsa v2는 아직 “나만의 작은 도구 + 실험용 인프라”에 가깝지만,
실제로 돌려보면서 몇 가지 인사이트를 얻었습니다.
1.
“스크린샷 → 코드”는 생각보다 많은 컨텍스트를 줄 수 있다.
•
버튼 이름, 컬럼 헤더, 주변 텍스트만으로도
프론트엔드 컴포넌트를 꽤 정확하게 찾을 수 있었습니다.
2.
코드베이스를 건드리지 않고도 “코드 에이전트”를 만들 수 있다.
•
기존 서비스에 SDK를 심지 않고,
•
GitHub + S3 스냅샷만으로도 꽤 많은 분석이 가능합니다.
3.
에이전트 설계가 모델 선택보다 중요하다.
•
같은 LLM Model 이라도 “어떤 순서로 툴을 실행시키고, 어떤 정보를 넘겨주는지”에 따라 결과 품질이 크게 달라졌습니다.
앞으로는 다음과 같은 방향으로 확장해볼 계획입니다.
•
더 많은 레포(데이터 파이프라인, 배치 잡 등) 연결
•
특정 요청에 대한 코드 경로를 기록·공유할 수 있는 기능
(예: “이 기능에 대한 Chezipsa 리포트 링크”를 문서에 첨부)
•
간단한 구조도(텍스트 기반 다이어그램)를 자동 생성해 주는 기능
•
멀티턴 대화를 지원해 “추가로 이 부분도 확인해줘” 같은 follow-up까지 처리
마무리
Chezipsa v2는 거창한 플랫폼이라기보다는,
“코드 읽기 노동”을 조금 덜어주는 작은 도구에서 출발했습니다.
하지만 스크린샷 한 장으로
•
어디서 코드를 시작해서
•
어떤 서비스와 API를 거쳐
•
어떤 비즈니스 로직으로 이어지는지까지
한 번에 설명해 줄 수 있다면,
개발자뿐만 아니라 기획/운영/CS 입장에서도 꽤 쓸모 있는 도구가 될 수 있다고 생각합니다.
이번 글에서는 Chezipsa v2의 배경, 요구사항, 아키텍처, 인프라, 구현 방식을 간단히 소개했습니다.
다음 글에서는 실제로 에이전트가 코드를 탐색하는 과정과,
“잘못 짚은 코드 경로를 어떻게 수정해 나갔는지” 같은 실패・개선 사례를 중심으로 더 깊게 다뤄보려고 합니다.
읽어주셔서 감사합니다.
혹시 글을 읽으면서 “우리 팀에도 이런 도구가 필요하겠다”는 생각이 들었다면,
언제든지 편하게 의견을 나눠보고 싶어요.
참고자료


작성자
관련된 글 더 보기















