


Amazon S3 비용을 고려할 필요가 있을까?
Amazon Simple Storage Service (이하 S3)는 값싸고 속도가 빨라서 가성비가 좋은 스토리지로 알려져 있습니다. 하지만 도리어 그런 인식 때문에 S3 비용의 적절성에 대해 잘못 판단할 가능성이 존재합니다. 이 글은 데이블의 S3 비용 절감 사례를 바탕으로 s3 비용을 체크하는 기준을 만들고 그것을 바탕으로 S3 비용을 낮추는데 도움이 될 수 있도록 작성했습니다.

클로드3 님께서 S3는 값싸고 빠르다고 인정했습니다. (Generated by Claude 3.5 Sonnet)
S3는 크게 두 가지 측면에서 비용이 발생합니다. 저장 용량 비용과 액세스 비용입니다. 데이블에서는 저장 용량 비용 개선을 위해 여러 가지 노력을 기울였기 때문에 여기에서는 저장 용량 비용에 관해서만 다루려고 합니다.
저장 용량 비용
아무리 가성비가 좋아도 저장 용량이 많으면 그에 비례해서 비용이 많이 나옵니다.
‘S3는 싸니까 괜찮아.’
아닙니다. 다른 스토리지들보다 상대적으로 싼 것 뿐입니다.
데이블은 S3 비용을 더 낮출 수 있는지 판단하기 위해서 아래의 세 가지 의문을 던졌습니다.
1.
현재 저장중인 데이터가 꼭 필요한가?
2.
보관중인 데이터를 얼마나 자주 사용하는가?
3.
어느 기간만큼 보관해야 하는가?
각 의문들에 대해 데이블의 사례를 예로 들어서 설명해보겠습니다. 단, 가상의 데이터 이름과 숫자를 사용할 것입니다.

S3 비용 정책에 관한 언급이 있으며, 이는 Asia Pacific (Seoul) Region 및 2024년 11월 기준입니다. 이후 아마존에서 S3 요금 정책을 변경한 경우를 감안해야 합니다.
요금 정책을 잘못 이해한 부분이 없는지 꼼꼼히 확인했지만 해석을 잘못한 경우가 있을 수 있으므로 양해 부탁드립니다. S3 비용을 면밀히 검토할 때는 https://aws.amazon.com/s3/pricing/ 를 확인하기 바랍니다.
현재 저장중인 데이터가 꼭 필요한가?
컨텐츠 추천 서비스와 광고 추천 서비스를 제공하는 데이블은 컨텐츠 추천 로그들과 광고 로그들이 시시각각 발생합니다. 또한 데이블이 계약해서 보유하고 있는 광고 지면에 대해 OpenRTB 표준을 따르는 실시간 경매 서버를 제공하고 있으며, 여기에서 입찰/낙찰 로그들이 끊임없이 발생합니다. 이러한 로그들은 데이블의 서비스 품질을 향상시키는데 사용하고 있습니다. 하지만 모든 로그들이 중요하고 필수적일까요?
2023년 중반까지 데이블의 주요 로그들을 저장한 S3 버킷의 일 비용은 50만원이었습니다. 데이터 중심 회사로서 이 정도 비용은 감수해야 한다는 의견도 있었고 S3는 싸니까 이 정도 비용은 괜찮다는 시각도 존재했습니다. 데이블은 ‘정말로 그러한가?’라는 의구심과 함께 버킷의 파일들에 대해 분석을 진행했습니다. 그 결과 사용성이 낮으면서도 용량을 많이 차지하는 로그들의 존재를 확인했습니다. 여러 차례 토론을 거쳐서 그런 로그들은 일부만 샘플링해서 저장하는 방향으로 결론 내렸고, S3 버킷의 저장 비용을 일 30만원으로 낮췄습니다.
처음부터 어떤 로그의 필요성을 가늠하기는 어렵습니다. 데이블 역시 몇 년이라는 시간 동안 그러한 로그의 저장 비용을 적지 않게 들였고, 그 로그가 필요 없다고 판단하기까지 여러 논의가 있었습니다.
회사가 발전하고 규모가 커질수록 새로운 서비스가 생기고 자연스럽게 새로운 로그가 발생할 것입니다. 그 때마다 로그 저장 비용을 내면서 필요성에 대한 판단을 유보해야 할까요? 그보다는 로그 저장 필요성에 대해 이렇게 판단해보려고 합니다.
1.
아직 필요성을 알 수 없는 어떤 로그 A를 저장하기 위해 드는 비용이 다른 로그들 대비 큰가?
a.
YES → 샘플링해서 저장하는 방안을 고려한다. 이후 샘플링한 로그를 분석하여 저장 필요성을 판단한다.
2.
만약 로그 A 대비 상대적으로 비용이 낮은 로그 B가 있고 로그 A의 일부 데이터가 로그 B에 필요하다고 하자. 로그 A를 저장하는 시스템과 로그 B를 저장하는 시스템이 서로 다르거나, 동일 시스템이라고 하더라도 서로 저장하는 플로우가 다른 경우 쉽게 하나로 합칠 수가 없다.
a.
로그 A를 캐시해놓고 로그 B에 덧붙여 저장한다.
b.
캐시를 구현하기 어렵다면 로그 A 전체를 저장하는 대신 필요한 정보만 선별적으로 저장한다.
보관중인 데이터를 얼마나 자주 사용하는가?
데이블에서 발생하는 로그들을 사용하는 패턴을 보면 대부분 1일 이내입니다. 1주 또는 1달 주기 배치로 로그를 조회하는 경우가 있지만 이는 일부 로그에만 해당하며, 장기간의 데이터를 읽는 배치는 로그 원본을 읽는 대신 로그 원본을 요약한 형태의 데이터를 읽도록 구성되어 있습니다. 이러한 사용 패턴에 맞춰서 보관중인 데이터에 대해, 자주 사용하지 않는 데이터는 저장 용량 비용을 덜 받는 스토리지로 옮기도록 설정하고 있습니다. 데이터 최초 저장 후 기간에 따라서 스토리지를 자동으로 옮기는 설정을 수명 주기 규칙(Lifecycle Rule)이라고 합니다. S3 저장 비용 절감의 최종 결과물은 바로 S3 수명 주기 규칙이라고 해도 과언이 아닙니다. 만약 저장 용량이 큰 주요 버킷들에 설정된 수명 주기 규칙이 하나도 없다면 비용 관리를 전혀 하지 않는 상황이므로 S3 비용을 과도하게 지불하고 있을 가능성이 매우 높습니다.
수명 주기 규칙(Lifecycle Rule)
S3 저장 비용 절감의 최종 결과물은 바로 S3 수명 주기 규칙이라고 해도 과언이 아닙니다. 만약 저장 용량이 큰 주요 버킷들에 설정된 수명 주기 규칙이 하나도 없다면 비용 관리를 전혀 하지 않는 상황이므로 S3 비용을 과도하게 지불하고 있을 가능성이 매우 높습니다.
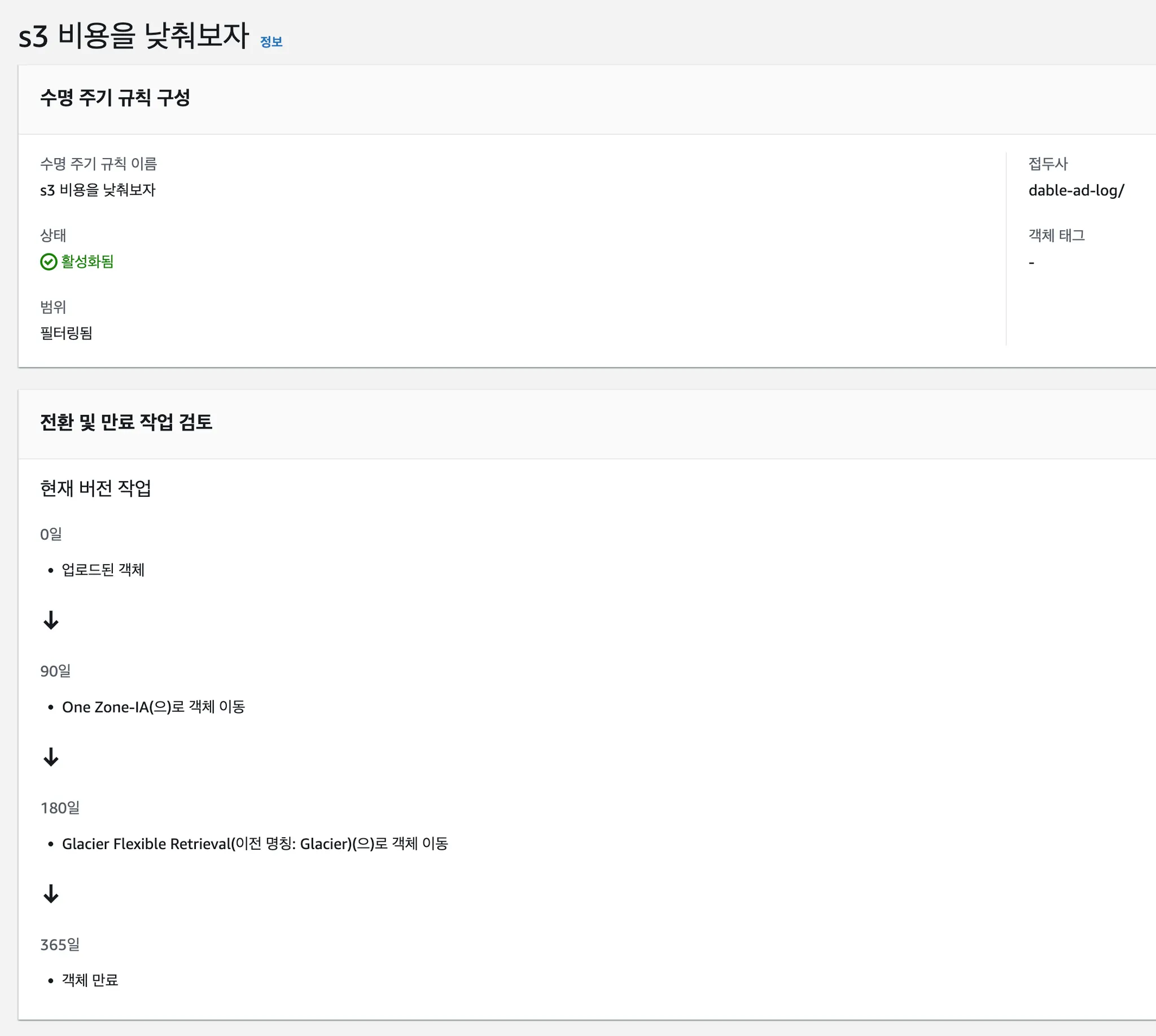
S3는 버킷별로 저장 비용을 관리하는 규칙인 수명 주기 규칙을 설정할 수 있습니다. 다음 예시는 기생성된 수명 주기 규칙 화면입니다.
•
규칙 이름 : 규칙 목록에 나오는 이름이므로 규칙 의 목적이 잘 드러나도록 정합니다.
•
접두사 : 버킷 루트를 기준으로 경로 접두사(path prefix)를 적어줍니다.
특정 접두사 아래의 모든 객체에 대해 수명 주기 규칙을 적용하려면 접두사 맨 마지막에 반드시 / (슬래쉬)가 있어야 합니다.
•
전환 및 만료 작업 검토
◦
수명 주기 규칙의 핵심입니다.
◦
현재 버전 작업 : 버킷 버저닝에 관한 것으로, 이 글의 내용을 벗어나기 때문에 자세한 내용은 생략하겠습니다.
◦
0일 : 처음 버킷에 파일이 생겼을 때 어떻게 할 것인지 결정할 수 있습니다. 기본적으로는 Standard 스토리지 클래스로 저장됩니다. 스토리지 클래스는 S3 저장 비용과 관련해서 매우 중요한 내용이므로 수명 주기 규칙 설명 이후에 따로 설명하겠습니다.
◦
90일 : 수명 주기 규칙은 며칠이 지나면 어떤 액션을 취하라는 식으로 만들 수 있습니다. 이 예시에서는 90일 지나면 One Zone-IA 스토리지 클래스로 이동하라고 설정했습니다.
◦
180일 : 180일이 지나면 Glacier Flexible Retrieval 이라는 스토리지 클래스로 이동하라고 설정했습니다.
◦
365일 : 이 기간이 지난 파일을 삭제하라고 설정했습니다.
스토리지 클래스
보관중인 데이터를 얼마나 자주 사용하는지 판단하는 과정이 곧 스토리지 클래스를 결정하는 과정입니다. 어떤 데이터 A를 매우 자주 사용한다면 Standard가 적합할 것이고, 어떤 데이터 B는 자주 사용하지 않지만 반드시 보관을 해야 한다면 Glacier 와 같이 저장 비용이 싼 스토리지 클래스를 고려할 수 있습니다.
위에서 언급한 데이터 A나 B처럼 스토리지 클래스를 선택하기 쉽다면 얼마나 좋을까요? 데이터의 필요성에 대한 판단이 어려운 것처럼 데이터 사용성 판단 역시 어렵습니다. 자주 사용하지 않을 것이라고 판단하고 Glacier 에 저장할 경우 액세스 비용이 상대적으로 매우 비싸기 때문에 상황에 따라 Standard-IA에 보관하는 것보다 비용이 더 나올 수 있습니다.
이러한 점 때문에 데이블은 지능 계층화 (Intelligent Tiering, 이하 IT) 스토리지 클래스를 선택했습니다. IT는 S3에서 프로그램적으로 파일들의 사용 패턴을 파악하고 스토리지 클래스를 알아서 이동해줍니다. 사용 패턴을 파악하는 비용을 별도로 내야 하지만 그 가격이 매우 싸기 때문에 무시해도 될 수준입니다. 따라서 데이블은 IT 사용을 적극 추천합니다. 주요 버킷에 수명 주기 규칙이 없거나 확신없이 만들었다면 아래 예시와 같이 설정하길 추천드립니다.
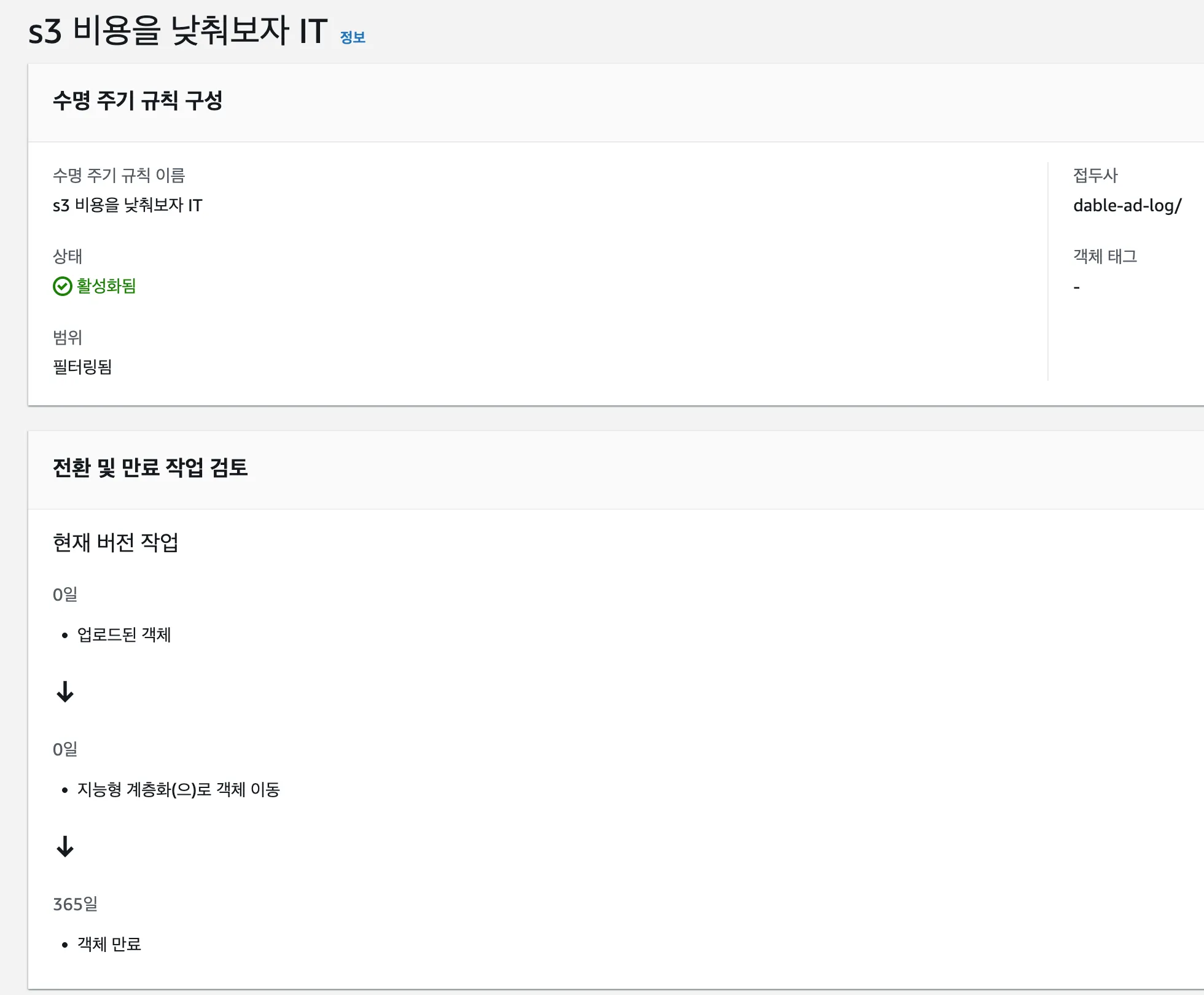
파일을 저장할 때 스토리지 클래스를 지정할 수 없을까?
할 수 있습니다.
이 동작이 필요한 이유는 수명 주기 규칙을 통해 스토리지 클래스 간에 데이터를 이동할 때 비용이 발생하기 때문입니다. 이 비용 자체는 매우 낮지만 생성하는 파일 개수가 매우 많은 환경에서는 개수만큼 곱하기로 계산하기 때문에 무시못할 비용이 발생할 수 있습니다.
만약 Standard가 아닌 IT를 사용하기로 결정했다면 IT 스토리지 클래스에 저장하도록 지정하면 됩니다.
먼저 가장 기본이 되는 AWS SDK for Java v2 예시를 살펴보겠습니다. PutObjectRequest 를 만들 때 storageClass(StorageClass.INTELLIGENT_TIERING) 호출을 통해 지정할 수 있습니다.
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.PutObjectRequest;
import software.amazon.awssdk.services.s3.model.StorageClass;
import java.nio.file.Paths;
public class S3StorageClassExample {
public static void main(String[] args) {
String bucketName = "your-bucket-name";
String keyName = "your-object-key";
String filePath = "path/to/your/file";
S3Client s3 = S3Client.create();
PutObjectRequest request = PutObjectRequest.builder()
.bucket(bucketName)
.key(keyName)
.storageClass(StorageClass.INTELLIGENT_TIERING)
.build();
s3.putObject(request, Paths.get(filePath));
System.out.println("File uploaded with specified storage class.");
}
}
Java
복사
Trino 또는 Spark 같은 분산 처리 시스템에서는 어떻게 할 수 있을까요? 각 제품에서 제공하는 매뉴얼에 설정 정보들을 찾아볼 수 있으므로 여기에서는 EMR 에 번들링된 Trino와 Spark 에서의 설정 방법을 제시하겠습니다.
EMR에 번들링된 Trino, Spark은 아마존에서 개발한 EMRFS 를 사용하도록 수정되어 있습니다. 따라서 각 제품의 매뉴얼에 나온 방법대로 하면 안 되고 반드시 EMRFS 에 대한 설정을 해야 합니다. 두 제품 모두 bootstrap 설정에서 아래와 같이 emrfs-site 설정으로 기술하면 됩니다.
{
...,
"configurations": [
{
"Classification": "emrfs-site",
"Properties": {
"fs.s3.storageClass": "INTELLIGENT_TIERING"
}
},
...
]
}
JSON
복사
EMR Spark 에서 emrfs-site 로 설정을 하더라도 iceberg 로 S3 에 파일을 생성할 경우에는 적용되지 않습니다. 이는 iceberg 라이브러리가 EMRFS를 사용하지 않기 때문입니다. 아마존에서 아직 iceberg 까지는 수정하지 못한 것으로 추정됩니다. spark-defaults 설정에 아래와 같이 기술하면 됩니다. 단, EMR Trino에서 iceberg 로 S3 에 파일을 생성할 경우에는 아직 적용할 방법이 없습니다.
{
...,
"configurations": [
{
"Classification": "spark-defaults",
"Properties": {
"spark.sql.catalog.iceberg": "org.apache.iceberg.spark.SparkCatalog",
...
"spark.sql.catalog.iceberg.s3.write.storage-class": "INTELLIGENT_TIERING"
}
},
...
]
}
JSON
복사
어느 기간만큼 보관해야 하는가?
보관 기간을 결정하는 요소는 데이터의 중요도와 성격입니다.
데이터의 중요도는 회사에서 제공하는 서비스에 의해서 결정됩니다. 기사 추천 및 광고 시스템을 제공하는 데이블은 기사 추천 이후 발생한 노출과 클릭 데이터, 광고 추천 이후 발생한 노출, 클릭 그리고 전환 데이터가 핵심 데이터입니다. 이러한 핵심 데이터는 장기간 보관해야 됩니다.
데이터의 성격은, 데이터의 크기, 법적인 요소 등이 있습니다. 데이터의 크기가 작다면 이런 비용 고민을 할 필요가 없을 것입니다. 법적인 요소의 경우, 예를 들어, 법적으로 의무 기간을 지켜야 하는 데이터입니다.
법적인 의무 보관 기간을 지켜야 하는 데이터가 아니라면 다음의 의문과 함께 고민을 해보면 어떨까 합니다.
•
데이터 분석시 원본 데이터가 반드시 필요한가?
데이블을 예로 들어보겠습니다. 대부분 데이터를 사용하는 패턴은 어떤 조합에서의 기사 노출 수, 클릭 수, 광고의 노출 수, 클릭 수, 광고 클릭 후 전환 발생 수와 같이 어떤 조합에 기반에서 숫자로 요약된 값을 조회하는 것입니다. 크기 비교를 해보면 원본 데이터가 100이라면 어떤 조합으로 요약된 숫자 값은 1 미만이라고 볼 수 있습니다. 이에 따라 데이블에서는 다음과 같은 스키마 형태(일부 예시)로 1시간 단위 요약 데이터를 만듭니다. 이를 알기 쉽게 Summary 라고 부르고 있습니다.
CREATE EXTERNAL TABLE fact_hourly.ad_summary
(
inventory_id STRING,
advertiser_id INT,
ad_campaign_id STRING,
ad_creative_id STRING,
impressions BIGINT,
viewable_impressions BIGINT,
clicks INT,
...
)
PARTITIONED BY (utc_basic_time STRING)
STORED AS PARQUET
SQL
복사
이러한 Summary 를 사용하는 경우 다음과 같은 장점들이 있습니다.
•
원본 데이터 대비 데이터 용량 감소로 장기간 보관 가능
•
데이터 분석시 소요되는 시간 감소
•
Athena 등에서 발생하는 데이터 스캔 비용 감소
하지만 Summary 만을 믿고 원본 데이터를 지울 수는 없습니다. 원본 데이터를 사용할 수 밖에 없는 데이터 분석 요구 사항이 반드시 발생하기 때문입니다. 또한 Summary 로직 업데이트 또는 오류로 인해서 Summary 백필이 필요한 경우에도 원본 데이터가 필요합니다.
이에 따라 데이블은 아래와 같은 하이브리드 형태로 데이터 보관 기간을 설정했습니다.
•
원본 데이터 : 데이터들의 중요도에 따라 3개월에서 1년 보관
◦
대부분의 경우 IT에 의해서 Infrequent Access 및 Archive Instant Access 에 저장되어 있습니다.
◦
Archive Access 및 Deep Archive Access 를 선택적으로 사용할 수 있는데 현재 검토중입니다.
•
Summary 데이터 : 데이블이 본격적으로 Summary 데이터를 만들기 시작한지 2년이 넘었지만 지운 적이 없습니다. 그만큼 비용 부담이 없기 때문입니다.
참고로 PARQUET 또는 ORC로 저장할 때 압축 알고리즘은 zstd 를 사용하고 있습니다.
IT 는 매직 불릿인가?
그렇지 않습니다.
IT의 경우 처음 생성된 이후 또는 최초 액세스 이후 30일 동안은 Frequent Access 스토리지에 저장하며, 30일 연속으로 액세스가 없는 파일들을 Infrequent Access로 옮기고, 90일 연속으로 액세스가 없으면 Archive Instant Access 로 옮깁니다. 즉, Archive Instant Access에 있던 파일을 단 1번이라도 액세스하면 Frequent Access로 옮기기 때문에 이 부분에서 비용 절감 효과가 떨어집니다.
만약 위와 같은 부분이 비용 낭비라고 판단되는 경우에는 S3 Glacier 를 고려해볼 수 있습니다. 단, S3 Glacier는 액세스 비용이 상대적으로 비싸기 때문에 보관 비용과 액세스 비용 간의 트레이드 오프를 계산해 봐야 합니다.
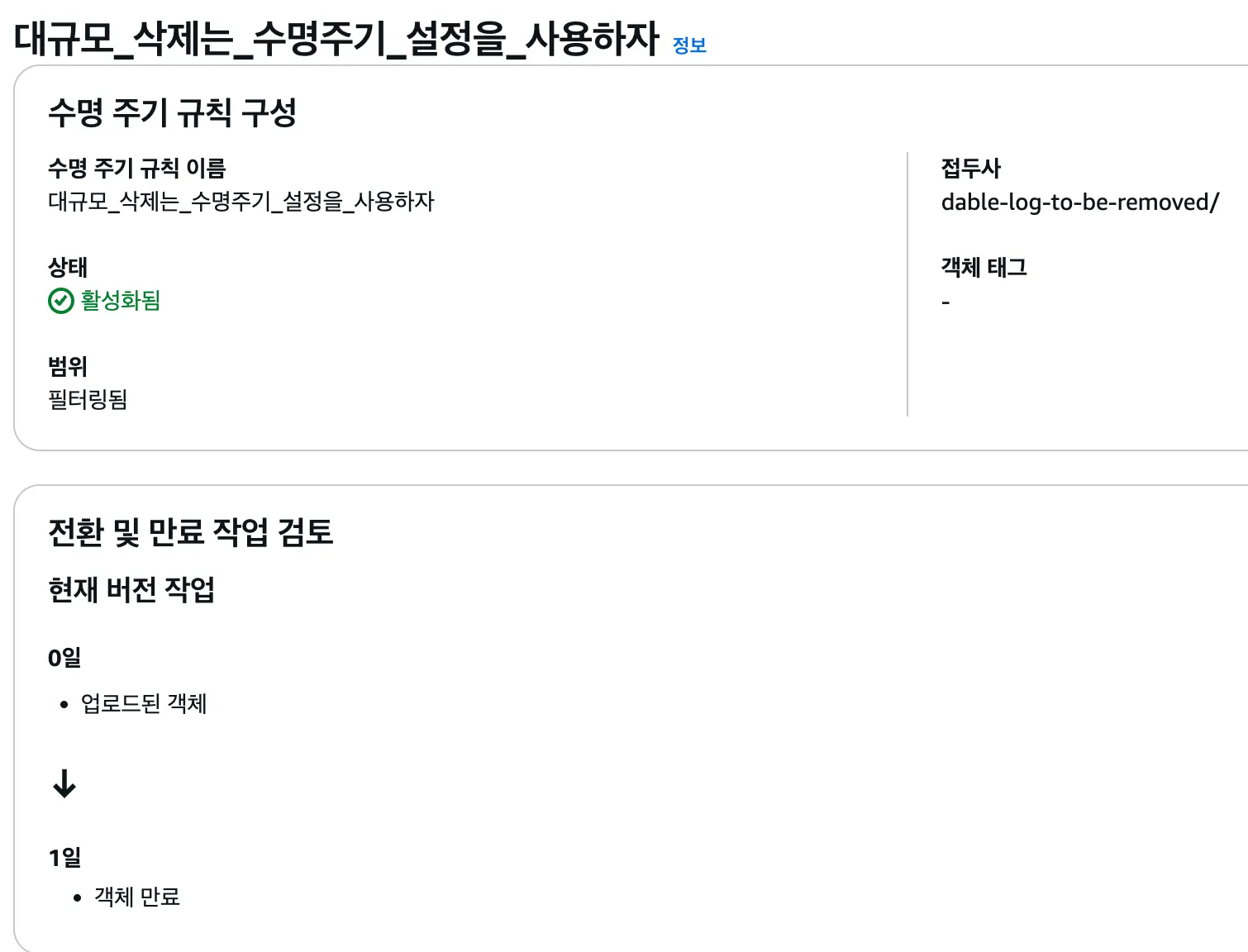
데이터 삭제 팁
현재 저장중인 데이터 중에서 필요없는 파일들을 삭제하기로 결정하셨나요? 저장 비용 절감을 위해서 바로 삭제하고 싶겠지만 스토리지 클래스에 따라서 파일 리스트 비용이 크게 발생할 수 있습니다. DELETE 비용은 무료라고 되어 있지만 DELETE를 수행하기 위한 프로그램(e.g. 아마존 웹 콘솔)들이 삭제할 파일들을 리스트해야 하기 때문에 여기에서 비용이 발생하게 됩니다.
데이블에서는 수동 삭제시 발생할 수 있는 불필요한 비용을 회피하기 위해서 수명 주기 규칙을 사용합니다. 수명 주기 규칙으로 삭제시 객체 만료 기간 최소값은 1일입니다. 만약 지워야 할 파일들의 사이즈가 너무 커서 하루 동안의 저장 비용이 파일 리스트 비용보다 더 크다고 계산되었다면 바로 삭제해도 될 것입니다.
참고자료

작성자
관련된 글 더 보기














