


안녕하세요, 데이블 AI 팀의 machine learning engineer 김명섭입니다. 이번 포스팅에서는 Spark가 어떻게 탄생하게 되었는지 살펴보고자 합니다. Hadoop부터, Spark의 최적화까지, 병렬 분산 처리의 전반적인 발전 흐름을 따라가보고자 합니다. 이 글은 대규모 데이터 처리에 관심이 있으신 엔지니어를 대상으로 작성되었습니다.
이번 포스팅에서 다룰 내용을 요약하면 아래와 같습니다. (사실 이번 포스팅에서는 하둡만 다룹니다.)
1.
데이터의 양이 폭증하며 더 이상 single machine에서는 데이터를 저장하고 처리하기가 어려워지기 시작함, 거기다 안정성이 높은 single machine은 비싸기까지 함
2.
상대적으로 저렴하지만, 성능이 낮고, 안정성도 낮은 다수의 machine을 이용하여 데이터를 저장할 수 없을까? → HDFS의 등장, 3 replica
3.
분산하여 안전하게 저장하는건 해결했고, 다수의 machine을 이용하여 연산을 처리할 수 있는 방법은 어떤 것이 있을까? → MapReduce의 등장
4.
MapReduce 좋은 건 알겠는데, RAM이 조금 남네? RAM은 휘발성이긴 한데, 이걸 좀 잘 써서 더 빠르게 병렬 분산 처리를 할 수는 없을까? → Spark의 등장 (2편에서)
1. Introduction
2000년대 초반, 인터넷의 급속한 발전과 함께 데이터의 양이 폭발적으로 증가하기 시작했습니다. 대규모 웹 서비스, 검색 엔진, 소셜 미디어 플랫폼 등이 대두되면서, 이들 서비스는 막대한 양의 데이터를 처리하고 저장해야 했습니다. 특히, Google과 같은 기업들은 웹 크롤링과 인덱싱, 대규모 데이터 분석을 위해 효율적이고 확장 가능한 데이터 저장 및 처리 시스템을 필요로 했습니다.
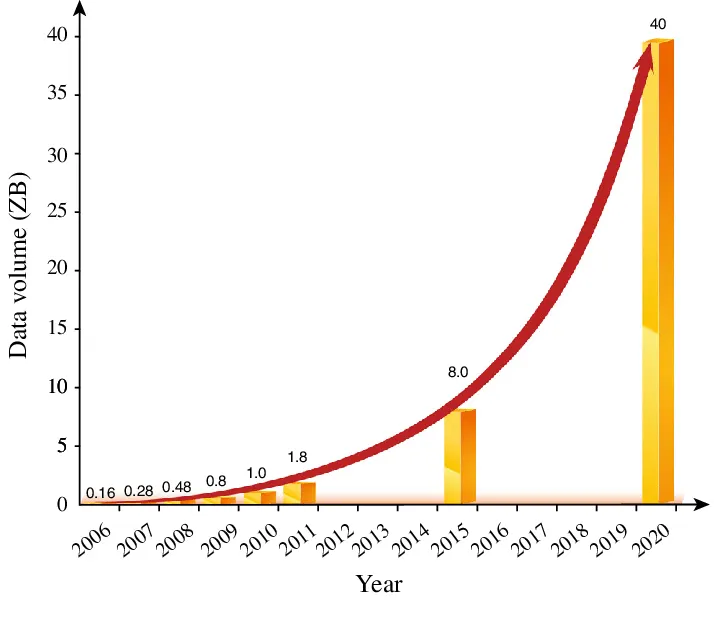
reference: Guo et al., 2014, Scientific big data and Digital Earth, Chinese Science Bulletin (Chinese Version) 59(12):1047
초기에는 전통적인 관계형 데이터베이스 관리 시스템(RDBMS)을 사용해 데이터를 처리하고 저장했으나, 데이터의 양이 기하급수적으로 증가하면서 이러한 시스템들은 여러가지 한계에 부딪혔습니다.
•
확장성의 한계: 단일 서버에 의존하는 기존의 데이터베이스 시스템은 데이터를 처리하고 저장하는데 있어 물리적 제한에 부딪혔습니다. 서버의 성능을 높이기 위해서는 더 강력한 하드웨어가 필요했지만, 이는 비용과 효율성 면에서 한계가 있었습니다.
•
비용 문제: 대규모 데이터 처리에 적합한 고성능 하드웨어는 매우 비쌌고, 이를 통해 대규모 데이터를 효율적으로 관리하는 것은 어려웠습니다.
•
데이터 처리 시간의 증가: 데이터가 증가함에 따라 처리 시간이 길어졌고, 특히 비정형 데이터(예: 로그 파일, 이미지, 동영상 등)를 다루는 데 있어 기존의 시스템은 비효율적이었습니다.
이러한 RDBMS의 한계를 극복하기 위해 하둡(Hadoop)이 등장하였습니다. 하둡은 대규모 데이터를 저장하고 처리하기 위해 설계된 오픈 소스 분산 컴퓨팅 프레임워크입니다. 하둡은 여러 대의 컴퓨터를 연결하여 하나의 강력한 시스템처럼 작동하도록 하여, 대량의 데이터를 효율적으로 처리할 수 있습니다. RDBMS를 사용할 경우에는 대규모 데이터 처리에 적합한 고성능, 고안전성의 하드웨어가 필요하였지만, 하둡을 사용할 경우에는 상대적으로 저렴한 다수의 컴퓨터에 데이터를 저장하고 관리할 수 있어 확장에 매우 용이하였습니다.

2. HDFS
하둡은 크게 Hadoop Distributed File System (HDFS)와 Map Reduce 두 가지 핵심 구성 요소로 나뉩니다. 우선적으로 HDFS는 데이터를 여러 대의 컴퓨터(노드)에 분산하여 저장하는 파일 시스템입니다. 데이터는 블록 단위로 쪼개져 여러 노드에 저장되며, 각 블록은 복제되어 여러 노드에 저장됨으로써 내구성과 가용성을 보장합니다. 예를 들자면, 하나의 파일은 128MB씩 쪼개져 여러 노드에 저장되고, 각 블록은 기본적으로 세 번 복제됩니다. 이를 3 replica라고 합니다.
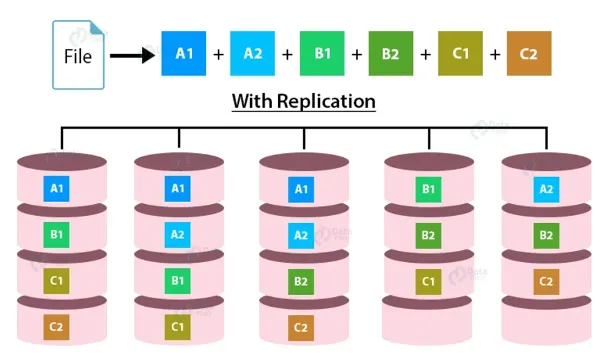
왜 이런 구조가 필요했을까요? 앞서, RDBMS 환경에서는 고성능, 고안전성의 하드웨어가 필요하고, 이러한 하드웨어는 매우 비싸다고 말씀드렸습니다. 하지만 하둡의 경우에는 상대적으로 저렴하지만, 성능이 낮고, 안전성이 떨어지는 하드웨어를 사용합니다. 이는 다시 말해, 데이터를 저장하고 있는 하드웨어에 문제가 생겨 데이터가 유실될 수 있음을 의미합니다. 하지만 3 replica를 보유하고 있게 되면, 한 대, 또는 두 대의 하드웨어에 문제가 생기더라도, 다른 복제본을 이용하여 원본 파일을 복원할 수 있습니다.
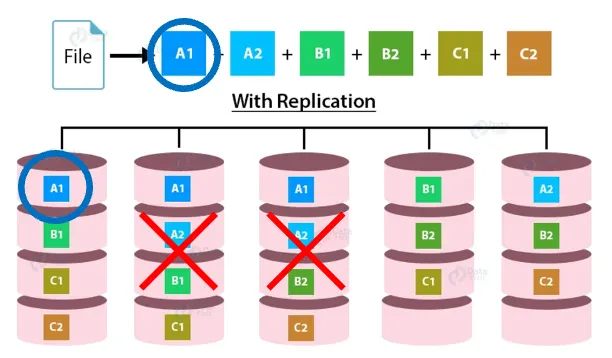
3. MapReduce
HDFS를 통해 상대적으로 가격이 싼 하드웨어를 이용하여 효율적으로 대용량 데이터를 관리할 수 있다는 사실을 알게 되었습니다. 그렇다면 대용량 데이터의 연산 등 처리는 어떻게 수행해야 할까요? 다수의 하드웨어에 분산되어 있는 데이터를 하나의 하드웨어로 모아 연산을 처리하는 방법이 있겠지만, 직관적으로 생각하기에도 이는 매우 비효율적입니다. Replica를 저장하고 있는 각 노드에서 연산을 수행하고, 수행한 연산의 결과를 집계할 수 있다면, 상대적으로 저렴한 하드웨어에서 병렬 분산하여 작업을 수행할 수 있을 것 같습니다. 이러한 개념에서 등장하게 된 것이 MapReduce입니다.
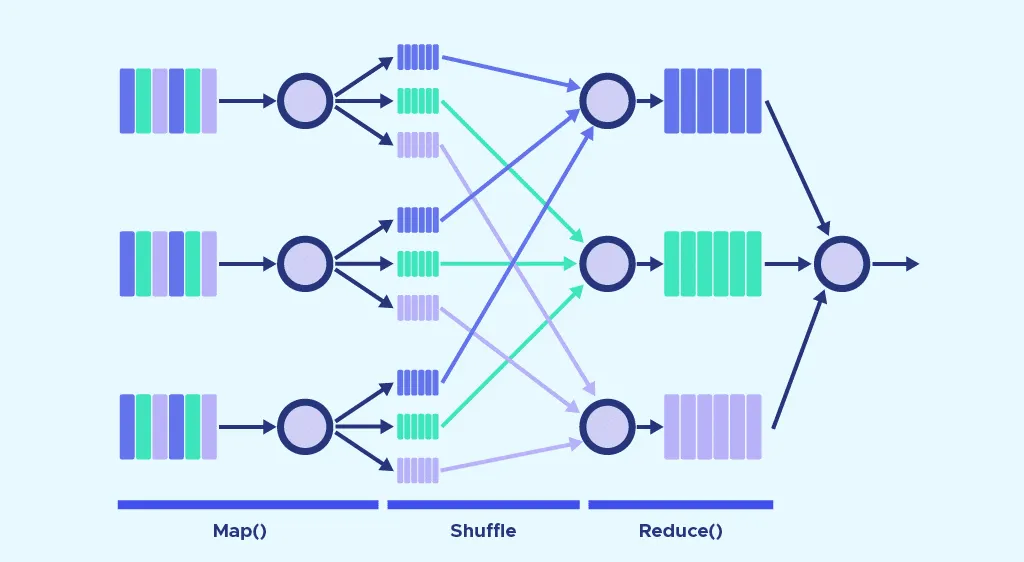
일반적으로 소프트웨어는 데이터보다 가볍습니다. 상대적으로 부담이 적은 코드를 각 replica를 저장하고 있는 분산 노드로 옮겨 연산을 수행하고, 그 연산 결과를 취합하는 과정을 반복하여 최종 결과물을 얻고자 하는 것이 MapReduce의 근간입니다. MapReduce는 일반적으로 Map → (Shuffle) → Reduce로 동작합니다. 아래와 같은 문서에서 각 알파벳의 수를 세는 것을 예시로, 각 단계에서 어떤 일들이 벌어지는지 살펴보도록 하겠습니다.
Success is not the key to happiness.
Happiness is the key to success.
If you love what you are doing, you will be successful.
Plain Text
복사
우선적으로 우리는 HDFS 환경에서의 MapReduce에 대해 알아보고 있는 중이기 때문에, 위의 문서가 문장 단위로 서로 다른 노드에 저장되어 있다고 가정하겠습니다. 편의 상 3 replica는 설명에서 제외하겠습니다.
노드 1
Success is not the key to happiness.
Plain Text
복사
노드 2
Happiness is the key to success.
Plain Text
복사
노드 3
If you love what you are doing, you will be successful.
Plain Text
복사
3. 1. Map
Map 단계의 목표는, 데이터를 읽어 중간 과정의 key-value의 쌍으로 변환하고, 분할된 데이터 조각을 처리하는 것입니다. 문서 내 알파벳 빈도를 세는 예제에서는 각 문자를 개별적으로 분석하여 (문자, 횟수) 쌍으로 매핑하는 작업을 수행할 수 있습니다. 이 작업은 각 노드별로 이루어지며, 아래와 같은 결과를 얻을 수 있습니다.
노드 1
(' ', 6),
('.', 1),
('a', 1),
('c', 2),
('e', 4),
('h', 2),
('i', 2),
('k', 1),
('n', 2),
('o', 2),
('p', 2),
('s', 6),
('t', 3),
('u', 1),
('y', 1)
Plain Text
복사
노드 2
(' ', 5),
('.', 1),
('a', 1),
('c', 2),
('e', 4),
('h', 2),
('i', 2),
('k', 1),
('n', 1),
('o', 1),
('p', 2),
('s', 6),
('t', 2),
('u', 1),
('y', 1)
Plain Text
복사
노드 3
(' ', 10),
(',', 1),
('.', 1),
('a', 2),
('b', 1),
('c', 2),
('d', 1),
('e', 4),
('f', 2),
('g', 1),
('h', 1),
('i', 3),
('l', 4),
('n', 1),
('o', 5),
('r', 1),
('s', 3),
('t', 1),
('u', 5),
('v', 1),
('w', 2),
('y', 3)
Plain Text
복사
3. 2. Shuffle
Shuffle 단계에서는 Map 단계의 결과를 key를 기준으로 그룹화합니다. 이 단계는 같은 key를 가진 (key, value) 쌍들이 같은 그룹으로 모이도록 합니다. 편의 상 같은 노드를 중심으로 모인다고 이해해 주시면 편할 것 같습니다. 이 과정이 다수의 노드에서 수행되므로, shuffle 과정은 네트워크를 이용하는 과정이며, 이 과정이 비효율적일 경우 많은 시간이 소요되게 됩니다.
노드 1
(' ', [6, 5, 10]),
(',', [1]),
('.', [1, 1, 1]),
('a', [1, 1, 2]),
('b', [1]),
('c', [2, 2, 2]),
('d', [1]),
('e', [4, 4, 4])
Plain Text
복사
노드 2
('f', [2]),
('g', [1]),
('h', [2, 2, 1]),
('i', [2, 2, 3]),
('k', [1, 1]),
('l', [4]),
('n', [2, 1, 1]),
('o', [2, 1, 5])
Plain Text
복사
노드 3
('p', [2, 2]),
('r', [1]),
('s', [6, 6, 3]),
('t', [3, 2, 1]),
('u', [1, 1, 5]),
('v', [1]),
('w', [2]),
('y', [1, 1, 3])
Plain Text
복사
3. 3. Reduce
Reduce 단계에서는 Shuffle 단계에서 그룹화된 데이터를 합쳐 최종 결과물을 만듭니다. 이 예제에서는 각 그룹의 값을 합산하여 해당 문자의 총 빈도를 계산합니다.
노드 1
(' ', 21),
(',', 1),
('.', 3),
('a', 4),
('b', 1),
('c', 6),
('d', 1),
('e', 12)
Plain Text
복사
노드 2
('f', 2),
('g', 1),
('h', 5),
('i', 7),
('k', 2),
('l', 4),
('n', 4),
('o', 8)
Plain Text
복사
노드 3
('p', 4),
('r', 1),
('s', 15),
('t', 6),
('u', 7),
('v', 1),
('w', 2),
('y', 5)
Plain Text
복사
최종 결과물은 아래와 같습니다.
(' ', 21),
(',', 1),
('.', 3),
('a', 4),
('b', 1),
('c', 6),
('d', 1),
('e', 12),
('f', 2),
('g', 1),
('h', 5),
('i', 7),
('k', 2),
('l', 4),
('n', 4),
('o', 8),
('p', 4),
('r', 1),
('s', 15),
('t', 6),
('u', 7),
('v', 1),
('w', 2),
('y', 5)
Plain Text
복사
Map, Shuffle, Reduce의 세 단계를 거쳐 대규모 데이터를 병렬로 처리하여 빠르고 효율적으로 원하는 결과를 얻을 수 있습니다.
4. Limitation
위의 예제의 경우 한 번의 Map → Shuffle → Reduce 연산으로 해결되는 문제이지만, 문제에 따라 다수의 MapReduce 연산을 반복해야 하는 경우도 존재할 수 있습니다. 이 경우에는 중간 결과물을 다시 HDFS에 저장하고, 이에 대해 MapReduce 연산을 수행하는 방식으로 문제를 해결합니다. 그러다보니, 느리고, 컴퓨터의 주된 자원 중 하나인 RAM을 최대한으로 활용하지 못한다는 문제점이 발생했습니다. Spark은 이러한 문제점을 해결하고자 등장하였습니다. 포스팅의 길이가 길어지는 관계로, RAM을 최대한으로 활용하며, 노드가 다운되었을 때, 데이터의 유실을 방지할 수 있도록 설계된 Spark에 대해서는 2편에서 다루도록 하겠습니다.
5. Conclusion
지금까지 아래와 같은 내용들을 살펴보았습니다.
1.
데이터의 양이 폭증하며 더 이상 single machine에서는 데이터를 저장하고 처리하기가 어려워지기 시작함, 거기다 안정성이 높은 single machine은 비싸기까지 함
2.
상대적으로 저렴하지만, 성능이 낮고, 안정성도 낮은 다수의 machine을 이용하여 데이터를 저장할 수 없을까? → HDFS의 등장, 3 replica
3.
분산하여 안전하게 저장하는건 해결했고, 다수의 machine을 이용하여 연산을 처리할 수 있는 방법은 어떤 것이 있을까? → MapReduce의 등장
4.
MapReduce 좋은 건 알겠는데, RAM이 조금 남네? RAM은 휘발성이긴 한데, 이걸 좀 잘 써서 더 빠르게 병렬 분산 처리를 할 수는 없을까? → Spark의 등장 (2편에서)
이 글이 병렬 분산 처리와 Spark의 등장 배경에 대해 이해하는데 도움이 되기를 바랍니다. 감사합니다.
작성자
관련된 글 더 보기









